4.5 Decision Rules
의사결정 규칙
의사결정 규칙은 조건(선행 사건이라고도 함)과 예측으로 구성된 간단한 IF-THEN 문입니다. 예를 들어 다음과 같습니다. 오늘 비가 오고 4월(조건)이면 내일 비가 올 것이다. 단일 결정 규칙 또는 여러 규칙 조합을 사용하여 예측할 수 있습니다.
의사 결정 규칙은 다음과 같은 일반적인 구조를 따릅니다.
조건이 충족되면 어떤 예측을 할 수 있다.
의사결정 규칙은 아마도 가장 해석 가능한 예측 모델일 것입니다.
그들의 IF-THEN 구조는 자연어와 의미적으로 유사하며, 우리가 생각하는 방식과 유사하며, 그 조건이 이해할 수 있는 특징으로부터 만들어 진다면, 조건의 길이는 AND와 결합된 feature=value 쌍의 수가 짧고, 규칙이 그리 많지 않습니다.
프로그래밍에서는 IF-THEN 규칙을 쓰는 것이 매우 자연스럽습니다.
머신러닝의 새로운 점은 의사결정 규칙이 알고리즘을 통해 학습된다는 것입니다.
알고리즘을 사용하여 주택의 가치를 예측하는 의사결정 규칙(low, medium 또는 high))을 배운다고 상상해보세요.
이 모델에 의해 학습된 한 가지 결정 규칙은 다음과 같습니다.
만약 한 집이 100평방미터보다 크고 정원이 있다면, 그 가치는 높습니다.
보다 공식적으로 다음과 같습니다.
만약 size>100 AND garden=1이면 value=high입니다.
의사결정 규칙을 세분화하겠습니다.
size>100은 IF-part의 첫 번째 조건입니다.- IF 파트의 두 번째 조건은
garden=1입니다. - 두 조건이 ‘AND’와 연결되어 새로운 조건을 만듭니다. 규칙이 적용되려면 둘 다 참이어야 합니다.
- 예측 결과(THEN-part)는
value=high입니다.
결정 규칙은 조건 내에서 하나 이상의 feature=value 문을 사용하며, ‘AND’로 추가할 수 있는 개수에 대한 상한은 없습니다.
예외는 명시적 IF-part가 없고 다른 규칙이 적용되지 않는 경우 적용되는 기본 규칙이지만 나중에 이에 대해 자세히 설명합니다.
의사결정 규칙의 유용성은 일반적으로 두 숫자로 요약됩니다. 지원(support) 및 정확성(accuracy)을 제공합니다.
규칙의 지원 또는 범위:
규칙 조건이 적용되는 관측치의 백분율을 지원이라고 합니다.
집값 예측에 대한 규칙 size=big AND location=good THEN value=high를 예로 들 수 있습니다.
1000채 중 100채가 크고 좋은 위치에 있다고 가정하면 규칙의 지원은 10%입니다.
예측(THEN-part)은 지원 계산에 중요하지 않습니다.
규칙의 정확성 또는 신뢰도:
규칙의 정확도는 규칙의 조건이 적용되는 관측치에 대한 올바른 클래스를 예측하는 데 있어 규칙이 얼마나 정확한지를 나타내는 척도입니다.
예를 들어 다음과 같습니다.
100가구가 size=big AND location=good THEN value=high, 85가치가 value=high, 14가구가 value=medium, 1가구가 value=low일때 라면, 규칙의 정확도는 85%입니다.
일반적으로 정확도와 지원 간에 절충(trade-off)이 이루어집니다. 조건에 특성을 더 추가하면 정확도가 높아지지만 지원이 줄어듭니다.
주택의 가치를 예측하기 위한 좋은 분류기를 만들려면 하나의 규칙뿐만 아니라 10 또는 20개의 규칙을 배워야 할 수도 있습니다. 그러면 상황이 더 복잡해질 수 있으며 다음 문제 중 하나에 부딪힐 수 있습니다.
- 규칙이 중복될 수 있습니다. 한 집의 가치를 예측하고 두 개 이상의 규칙이 적용되고 모순된 예측을 한다면 어떨까요?
- 규칙이 적용되지 않습니다. 주택의 가치를 예측하고 싶은데 규칙이 적용되지 않으면 어떻게 해야 합니까?
여러 규칙을 결합하기 위한 두 가지 주요 전략이 있습니다. 의사결정 목록(순서있음) 및 의사결정 집합(순서없음)입니다. 두 전략 모두 중복 규칙 문제에 대한 서로 다른 해결책을 의미합니다.
결정 목록(decision list)*은(는) 의사결정 규칙에 순서를 도입합니다. 예를 들어 첫 번째 규칙의 조건이 참이면 첫 번째 규칙의 예측을 사용합니다. 그렇지 않으면 다음 규칙으로 이동하여 적용 여부를 확인합니다. 의사 결정 목록은 적용되는 목록에서 첫 번째 규칙의 예측만 반환하여 규칙 중첩 문제를 해결합니다.
결정 집합(decision set)은 일부 규칙이 더 높은 투표 권한을 가질 수 있다는 점을 제외하면 규칙의 민주주의와 유사합니다. 집합에서 규칙은 상호 배타적이거나 개별 규칙 정확도 또는 기타 품질 측정에 의해 가중될 수 있는 다수결 투표와 같은 충돌을 해결하기 위한 전략이 있습니다. 여러 규칙이 적용될 경우 해석에 문제가 생길 수 있습니다.
의사 결정 목록과 집합 모두 관측치에 규칙이 적용되지 않는 문제를 겪을 수 있습니다. 이 문제는 기본 규칙을 도입하여 해결할 수 있습니다. 기본 규칙은 다른 규칙이 적용되지 않을 때 적용되는 규칙입니다. 기본 규칙의 예측은 대개 다른 규칙에서 다루지 않는 데이터 지점의 가장 빈번한 클래스입니다. 규칙 집합 또는 목록이 전체 특성 공간을 포괄하는 경우 이를 전체 특성이라고 합니다. 기본 규칙을 추가하면 집합 또는 목록이 자동으로 전체로 바뀝니다.
자료로부터 규칙을 배우는 방법은 여러 가지가 있는데, 이 책은 모든 것을 다루는지 않습니다. 이 장에서는 그 중 세 가지를 보여 줍니다. 알고리즘은 학습 규칙을 위한 다양한 일반적인 아이디어를 다루기 위해 선택되었습니다. 따라서 이 세 알고리즘은 모두 매우 다른 접근 방식을 나타냅니다.
- OneR는 단일 특성에서 규칙을 학습합니다. OneR은 단순성, 해석성 및 벤치마크로서의 사용이 특징입니다.
- Sequential covering은 규칙을 반복적으로 학습하고 새 규칙에서 다루는 데이터 지점을 제거하는 일반적인 절차입니다. 이 절차는 많은 규칙 학습 알고리즘에서 사용됩니다.
- Bayesian Rule Lists는 미리 확인된 빈도 패턴을 Bayesian 통계를 사용하여 의사결정 목록에 결합합니다. 미리 확인된 패턴을 사용하는 것은 많은 규칙 학습 알고리즘에서 사용되는 일반적인 접근 방식입니다.
가장 간단한 접근 방법부터 시작하겠습니다. 규칙을 학습하는 데 가장 적합한 단일 특성을 사용하는 것입니다.
단일 특성에서 규칙을 학습 (OneR)
Holte(1993)1가 제안한 OneR 알고리즘은 가장 단순한 규칙 유도 알고리즘 중 하나입니다. 모든 특성에서 OneR은 관심 결과에 대한 가장 많은 정보를 포함하는 특성을 선택하고 이 특성에서 의사 결정 규칙을 만듭니다.
“하나의 규칙”을 나타내는 OneR이라는 이름에도 불구하고 알고리즘은 두 개 이상의 규칙을 생성합니다. 이는 실제로 선택한 최상의 특성 값당 하나의 규칙입니다. 더 나은 이름은 OneFeatureRules입니다.
알고리즘은 간단하고 빠릅니다.
- 적절한 간격을 선택하여 연속형 특성을 범주화합니다.
- 각 특성에 대해 다음을 수행합니다.
- 특성 값과 (범주) 결과 사이에 교차 테이블을 만듭니다.
- 특성의 각 값에 대해 이 특정 특성 값을 가진 관측치의 가장 빈번한 클래스를 예측하는 규칙을 만듭니다(교차 표에서 확인할 수 있음).
- 특성에 대한 규칙의 총 오류를 계산합니다.
- 총 오류가 가장 작은 특성을 선택합니다.
OneR은 선택한 특성의 모든 수준을 사용하기 때문에 항상 데이터 집합의 모든 관측치를 포함합니다. 누락된 값은 추가 특성 값으로 처리하거나 미리 귀속될 수 있습니다.
OneR 모델은 분할이 하나만 있는 의사결정 트리입니다. 분할은 CART와 같이 반드시 이진법일 필요는 없지만 고유한 특성 값의 수에 따라 다릅니다.
OneR에서 가장 적합한 특성을 선택하는 예를 살펴보겠습니다. 다음 표는 가치(value), 위치(location), 크기(size) 및 애완동물 허용 여부(pets)에 대한 정보를 포함하는 주택에 대한 인공 데이터 집합를 보여 줍니다. 우리는 집의 가치를 예측할 수 있는 간단한 모델을 배우고 싶습니다.
| location | size | pets | value |
|---|---|---|---|
| good | small | yes | high |
| good | big | no | high |
| good | big | no | high |
| bad | medium | no | medium |
| good | medium | only cats | medium |
| good | small | only cats | medium |
| bad | medium | yes | medium |
| bad | small | yes | low |
| bad | medium | yes | low |
| bad | small | no | low |
OneR은 각 특성와 결과 사이에 교차 테이블을 생성합니다.
| Level | value=low | value=medium | value=high |
|---|---|---|---|
| location=bad | 3 | 2 | 0 |
| location=good | 0 | 2 | 3 |
| Level | value=low | value=medium | value=high |
|---|---|---|---|
| size=big | 0 | 0 | 2 |
| size=medium | 1 | 3 | 0 |
| size=small | 2 | 1 | 1 |
| Level | value=low | value=medium | value=high |
|---|---|---|---|
| pets=no | 1 | 1 | 2 |
| pets=only cats | 0 | 2 | 0 |
| pets=yes | 2 | 1 | 1 |
각 특성에 대해 테이블 행을 하나씩 살펴봅니다.
각 특성 값은 규칙의 IF-부분입니다.
이 특성 값을 가진 관측치의 가장 일반적인 클래스가 THEN-분에 해당하는 예측값입니다.
예를 들어, small, medium, big 수준의 크기 특성은 세 가지 규칙이 있습니다.
각 특성에 대해 생성된 규칙의 총 오류율(오차의 합)을 계산합니다.
위치 특성은 bad과 good의 가능한 값을 가집니다.
나쁜 곳에 있는 집의 가장 빈도가 높은 가치는 low이며, 우리가 low을 예측으로 사용할 때, 우리는 두 개의 집이 medium 가치를 가지고 있기 때문에 두 개의 실수를 했습니다.
좋은 곳에 있는 집의 예측가치는 high이고, 두 집은 medium이기 때문에 우리는 두 가지 실수를 했습니다.
위치 특성을 사용하여 발생하는 오류는 4/10이며, 크기 특성은 3/10이고, 애완동물 특성은 4/10입니다.
크기 특성은 오류가 가장 낮은 규칙을 생성하며 최종 OneR 모델에 사용됩니다.
IF size=small THEN value=small
IF size=medium THEN value=medium
IF size=big THEN value=high
OneR은 가능한 레벨이 여러 개인 특성를 선호합니다. 이러한 특성는 대상에 더 쉽게 적합할 수 있기 때문입니다. 노이즈만 포함하고 신호는 없는 데이터 집합을 상상해 보십시오. 즉, 모든 특성이 랜덤 값을 사용하며 대상에 대한 예측 값이 없습니다. 일부 특성은 다른 특성보다 더 많은 수준을 가집니다. 이제 레벨이 더 높은 특성이 더 쉽게 과적합될 수 있습니다. 데이터에서 각 관측치에 대해 별도의 레벨이 있는 특성은 전체 학습 데이터 집합를 완벽하게 예측할 수 있습니다. 해결책은 데이터를 학습 및 검증 집합로 나누고, 학습 데이터에 대한 규칙을 학습하고, 검증 집합에 특성을 선택하여 총 오류를 평가하는 것입니다.
동점(tie)는 다른 문제입니다. 즉, 두 특성이 동일한 총 오류를 발생시키는 경우입니다. OneR은 오류가 가장 낮은 첫 번째 특성 또는 카이 제곱 검정의 p-값이 가장 낮은 특성를 선택하여 침목을 해결합니다.
예시
실제 데이터를 사용하여 OneR을 사용해 보겠습니다. 자궁경부암 분류 과제를 사용하여 OneR 알고리즘을 테스트합니다. 모든 연속 입력 특성이 5개의 정량형태로 구분되었습니다. 다음 규칙이 생성됩니다.
| Age | prediction |
|---|---|
| (12.9,27.2] | Healthy |
| (27.2,41.4] | Healthy |
| (41.4,55.6] | Healthy |
| (55.6,69.8] | Healthy |
| (69.8,84.1] | Healthy |
연령 특성는 OneR에 의해 최상의 예측 특성로 선택되었습니다. ‘암(cancer)’은 드물기 때문에, 각 규칙에서 대다수의 계층과 예측된 라벨은 항상 ‘건강(healthy)’이기 때문에 다소 도움이 되지 않습니다. 이 불균형 사례에서 레이블 예측을 사용하는 것은 이치에 맞지 않습니다. 암에 걸린 여성의 비율과 함께 ‘연령’ 간격과 암/건강 사이의 교차 테이블이 더 유용합니다.
| Level | # Healthy | # Cancer | P(Healthy) |
|---|---|---|---|
| Age=(12.9,27.2] | 477 | 26 | 0.95 |
| Age=(27.2,41.4] | 290 | 25 | 0.92 |
| Age=(41.4,55.6] | 31 | 4 | 0.89 |
| Age=(55.6,69.8] | 1 | 0 | 1.00 |
| Age=(69.8,84.1] | 4 | 0 | 1.00 |
하지만 해석하기 전에 다음을 수행합니다. 모든 특성와 모든 값에 대한 예측이 정상이므로 전체 오류율은 모든 특성에 대해 동일합니다. 총 오류의 동점은 기본적으로 오류율이 가장 낮은 특성(여기서는 모든 특성이 55/858 포함)의 첫 번째 특성을 사용하여 해결되며, 이는 연령 득성을 나타냅니다.
OneR은 회귀 분석 문제를 지원하지 않습니다. 그러나 연속적인 결과를 간격으로 잘라냄으로써 회귀 작업을 분류 작업으로 변환할 수 있습니다. 이 기술을 사용하여 자전거 수를 4분위수(0-25%, 25-50%, 50-75%, 75-100%)로 줄임으로써 대여 자전거의 수를 예측합니다. 다음 표에는 OneR 모델을 적용한 후 선택한 특성이 나와 있습니다.
| mnth | prediction |
|---|---|
| JAN | [22,3152] |
| FEB | [22,3152] |
| MAR | [22,3152] |
| APR | (3152,4548] |
| MAY | (5956,8714] |
| JUN | (4548,5956] |
| JUL | (5956,8714] |
| AUG | (5956,8714] |
| SEP | (5956,8714] |
| OKT | (5956,8714] |
| NOV | (3152,4548] |
| DEZ | [22,3152] |
선택한 특성은 월입니다. 월별 특성에는 12가지 특성이 있습니다(워매!). 이는 대부분의 다른 특성보다 많은 수치입니다. 따라서 과적합의 위험이 있습니다. 좀 더 낙관적인 측면: 월별 특성은 계절적 추세(예: 겨울에 임대된 자전거가 적음)를 처리할 수 있으며 이러한 예측은 합리적으로 보입니다.
이제 간단한 OneR 알고리즘에서 몇 가지 특성으로 구성된 복잡한 조건을 가진 규칙을 사용하여 보다 복잡한 절차로 이동합니다. Sequential Covering입니다.
Sequential Covering
Sequential Covering은 규칙별로 전체 데이터 집합 규칙을 포함하는 의사결정 목록(또는 집합)을 만들기 위해 단일 규칙을 반복적으로 학습하는 일반적인 절차입니다. 많은 규칙 학습 알고리즘은 Sequential Covering 알고리즘의 변형입니다. 본 장에서는 주요 방법을 소개하고 예제에 대한 순차적 커버 알고리즘의 변형인 RIPPER를 사용합니다.
아이디어는 간단합니다. 먼저 일부 데이터 지점에 적용되는 올바른 규칙을 찾습니다. 규칙에서 다루는 모든 데이터 지점을 제거합니다. 데이터 포인트는 포인트가 올바르게 분류되었는지 여부에 관계없이 조건이 적용될 때 적용됩니다. 더 이상의 포인트가 남지 않거나 다른 정지 조건이 충족될 때까지 나머지 포인트로 적용된 포인트의 규칙 학습 및 제거를 반복합니다. 결과는 의사결정 목록입니다. 적용된 데이터 지점을 반복적으로 학습하고 제거하는 이러한 접근 방식을 “분리 및 조정”이라고 합니다.
데이터의 일부를 포함하는 단일 규칙을 생성할 수 있는 알고리즘이 이미 있다고 가정합니다. 두 클래스에 대한 순차적 포함 알고리즘(one positive, one negative)은 다음과 같이 작동합니다.
- 빈 규칙 목록(rlist)으로 시작합니다.
- 규칙 r을 학습합니다.
- 규칙 목록이 특정 임계값보다 낮다면(또는 참이 아니라면).
- rlist에 규칙 r을 추가합니다.
- 규칙 r에서 다루는 모든 데이터 지점을 제거합니다.
- 나머지 데이터에 대한 다른 규칙을 학습합니다.
- 의사결정 목록을 반환합니다.

그림 4.19: 이 알고리즘은 특성 공간을 단일 규칙으로 순차적으로 커버하고 해당 규칙에서 이미 다루고 있는 데이터 지점을 제거하는 방식으로 작동합니다. 시각화를 위해 x1 및 x2 특성은 연속적이지만 대부분의 규칙 학습 알고리즘에는 범주형 특성이 필요합니다.
예를 들어 다음과 같습니다.
당사는 크기와 위치, 애완동물 허용 여부를 기준으로 주택의 가치를 예측하는 작업과 데이터 집합를 보유하고 있습니다.
첫 번째 규칙은 다음과 같습니다.
size=big와 location=good이면 value=high다.
그런 다음 데이터 집합에서 좋은 위치에 있는 모든 대형 주택을 제거합니다.
나머지 데이터로 다음 규칙을 학습합니다.
만약 location=good면 value=medium입니다.
이 규칙은 좋은 위치에 큰 집이 없고 중간 및 작은 집만 좋은 위치에 있는 데이터에서만 학습됩니다.
다중 클래스의 경우 접근 방식을 수정해야 합니다. 첫째, 그 클래스는 빈도을 증가시킴으로써 순서를 정합니다. Sequential Covering 알고리즘은 최소 공통 클래스로 시작하여 규칙을 학습하고, 적용된 모든 관측치를 제거한 다음, 두 번째 최소 공통 클래스로 이동합니다. 현재 클래스는 항상 positive 클래스로 취급되며, 빈도가 높은 클래스는 negative 클래스에서 모두 결합됩니다. 마지막 클래스가 기본 규칙입니다. 이를 분류상 일 대 다 전략이라고도 합니다.
우리는 어떻게 하나의 규칙을 배울 수 있을까요? OneR 알고리즘은 항상 전체 특성 공간을 포함하므로 여기서는 무용지물이 될 수 있습니다. 하지만 다른 많은 방법들이 있습니다. 한 가지 방법은 Beam Search를 사용하여 의사 결정 트리에서 단일 규칙을 학습하는 것입니다.
- 의사결정 트리를 학습합니다(CART 또는 다른 트리 학습 알고리즘 사용).
- 루트 노드에서 시작하여 가장 순수한 노드(예: 가장 낮은 오분류 속도)를 다시 선택합니다.
- 터미널 노드의 다수 클래스가 규칙 예측으로 사용됩니다. 해당 노드로 연결되는 경로가 규칙 조건으로 사용됩니다.
다음 그림은 트리에서 Beam Search를 보여 줍니다.
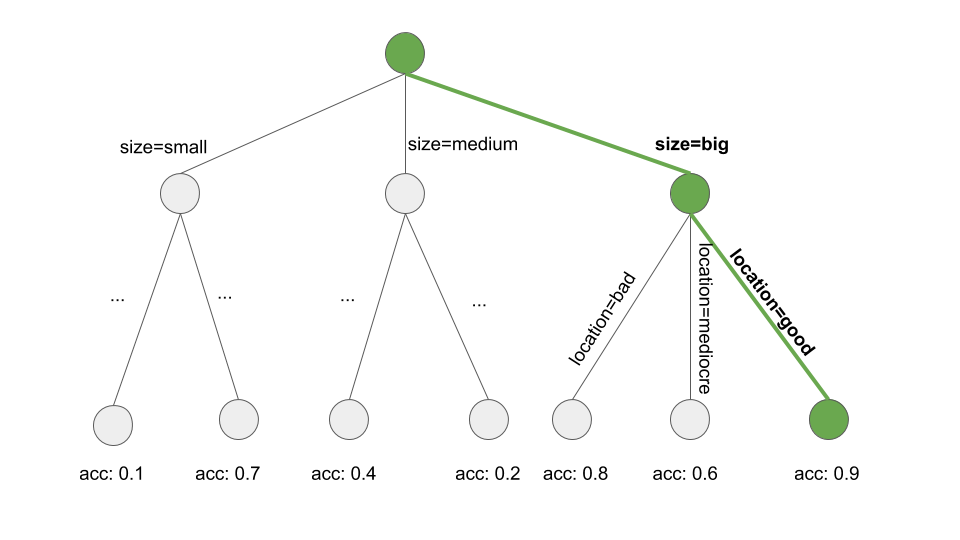
그림 4.19: 의사결정 트리를 통해 경로를 검색하여 규칙을 학습합니다. 관심 대상을 예측하기 위해 의사결정 트리를 키웁니다. 우리는 루트 노드에서 시작하여, 탐욕스럽고 반복적으로 순수한 부분집합(예: 최고 정확도)을 지역적으로 생성하는 경로를 따라 모든 분할 값을 규칙 조건에 추가합니다. 결국 다음과 같습니다: 만약 location=good와 size=big이면, value=high이다.
단일 규칙을 배우는 것은 검색 문제입니다. 여기서 검색 공간은 가능한 모든 규칙의 공간입니다. 검색의 목표는 일부 기준에 따라 최적의 규칙을 찾는 것입니다. 다음과 같은 다양한 검색 전략이 있습니다. hill-climbing, beam search, exhaustive search, best-first search, ordered search, stochastic search, top-down search, bottom-up search 등이 있습니다.
Cohen(1995)2의 RIPPER(Repeated Incremental Pruning to Produce Error Reduction)는 Sequential Covering 알고리즘의 변형입니다. RIPPER는 좀 더 정교하고 사후 처리 단계(규칙 제거)를 사용하여 의사 결정 목록(또는 집합)을 최적화합니다. RIPPER는 순서 또는 순서 없는 모드로 실행될 수 있으며 의사결정 목록 또는 의사결정 집합를 생성할 수 있습니다.
예시
예를 들어 RIPPER를 사용할 것입니다.
RIPPER 알고리즘은 자궁경부암에 대한 분류 작업에서 어떤 규칙도 찾지 않습니다.
회귀 작업에 RIPPER를 사용하여 자전거 대여 수를 예측하면 일부 규칙이 발견됩니다. RIPPER는 분류에만 사용되므로 자전거 수는 범주형 결과로 변경해야 합니다. 저는 자전거 숫자를 4분위수로 나눴습니다. 예를 들어 (4548, 5956)는 4548과 5956 사이의 예상 자전거 수를 포함하는 간격입니다. 다음 표는 학습된 규칙의 의사결정 목록을 보여줍니다.
| rules |
|---|
| (days_since_2011 >= 438) and (temp >= 17) and (temp <= 27) and (hum <= 67) => cnt=(5956,8714] |
| (days_since_2011 >= 443) and (temp >= 12) and (weathersit = GOOD) and (hum >= 59) => cnt=(5956,8714] |
| (days_since_2011 >= 441) and (windspeed <= 10) and (temp >= 13) => cnt=(5956,8714] |
| (temp >= 12) and (hum <= 68) and (days_since_2011 >= 551) => cnt=(5956,8714] |
| (days_since_2011 >= 100) and (days_since_2011 <= 434) and (hum <= 72) and (workingday = WORKING DAY) => cnt=(3152,4548] |
| (days_since_2011 >= 106) and (days_since_2011 <= 323) => cnt=(3152,4548] => cnt=[22,3152] |
해석은 간단합니다. 조건이 적용되면 오른쪽의 자전거 수 간격을 예측합니다. 마지막 규칙은 관측치에 적용되는 다른 규칙이 없을 때 적용되는 기본 규칙입니다. 새 관측치를 예측하려면 목록 맨 위에서 시작하여 규칙이 적용되는지 여부를 확인합니다. 조건이 일치하면 규칙의 오른쪽은 이 관측치에 대한 예측입니다. 기본 규칙은 항상 예측을 보장합니다.
Bayesian Rule Lists
이 섹션에서는 의사결정 목록을 학습하기 위한 또 다른 접근 방식을 보여드리며, 이 방법은 다음과 같습니다.
- 의사결정 규칙의 조건으로 사용할 수 있는 데이터에서 빈번한 패턴을 미리 파악합니다.
- 미리 확인된 규칙의 선택 항목에서 의사결정 목록을 학습합니다.
이 방법를 사용하는 특정 접근 방식을 Bayesian Rule Lists(Letham et al., 2015)3 또는 BRL이라고 합니다. BRL은 Bayesian 통계를 사용하여 FP-tree 알고리즘(Borgelt 2005)4으로 미리 확인된 빈번한 패턴에서 의사결정 목록을 학습합니다.
BRL의 첫 번째 단계부터 천천히 시작하겠습니다.
빈번한 패턴 사전 확인
빈번한 패턴은 특성 값의 빈번한(공동) 발생입니다.
BRL 알고리즘의 사전 처리 단계로서 특성(이 단계에서는 표적 결과가 필요하지 않음)을 사용하여 자주 발생하는 패턴을 추출합니다.
패턴은 size=medium과 같은 단일 특성 값 또는 size=medium AND location=bad와 같은 특성 값의 조합일 수 있습니다.
패턴의 빈도는 데이터 집합의 지원으로 측정됩니다.
\[Support(x_j=A)=\frac{1}n{}\sum_{i=1}^nI(x^{(i)}_{j}=A)\]여기서 A는 특성 값입니다. n은 데이터 집합의 데이터 지점 수이고 I는 관측치 i의 \(x_j\) 특성이 0 레벨이면 1을 반환하는 항등 함수입니다.
집값 데이터 집합에서 20%의 주택에 발코니가 없고 80%가 하나 이상이면 balcony=0 패턴에 대한 지원은 20%입니다.
또한 balcony=0 AND pets=allowed와 같이 특성 값의 조합에 대해서도 지원을 측정할 수 있습니다.
이러한 빈번한 패턴을 찾기 위한 많은 알고리즘이 있습니다. 예를 들어 Apriori 또는 FP-Growth가 있습니다. 무엇을 사용하든 별로 중요하지 않습니다. 패턴이 발견되는 속도만 다르고 결과 패턴은 항상 동일합니다.
어떻게 Apriori 알고리즘이 빈번한 패턴을 찾는지 대략적으로 알려드리겠습니다. Apriori 알고리즘은 두 부분으로 구성되어 있습니다. 첫 번째 부분은 빈번한 패턴을 찾아내고 두 번째 부분은 그것들로부터 연결 규칙을 만듭니다. BRL 알고리즘의 경우, Apriori의 첫 부분에서 생성되는 빈번한 패턴에만 관심이 있습니다.
첫 번째 단계에서 Apriori 알고리즘은 사용자가 정의한 최소 지원보다 큰 지원을 가진 모든 특성 값으로 시작합니다.
이용자가 최소지원이 10%이어야 하고 5%에 불과한 주택이 size=big를 갖는다면 그 특징값을 없애고 size=medium와 size=small만 패턴으로 유지하겠습니다.
이는 집들이 데이터에서 제거되었다는 것을 의미하는 것이 아니라 단지 size=big가 빈번한 패턴으로 반환되지 않는다는 것을 의미합니다.
Apriori 알고리즘은 단일 특성 값의 빈번한 패턴을 기반으로 점점 더 높은 수준의 특성 값의 조합을 반복적으로 찾으려고 합니다.
패턴은 feature=value 문과 논리 AND(예: size=medium AND location=bad)를 결합하여 작성합니다.
최소 지원보다 낮은 지원를 사용하여 생성된 패턴은 제거됩니다.
우리는 모든 빈번한 패턴을 확인했습니다.
빈번한 패턴의 어떤 부분집합도 다시 빈번하게 일어나는데, 이를 Apriori 속성이라고 합니다.
직관적으로 다음과 같습니다.
패턴에서 조건을 제거하면 축소된 패턴은 더 많은 데이터 포인트 또는 동일한 데이터 포인트 수를 포함할 수 있을 뿐 아니라 더 적은 데이터 포인트도 포함할 수 있습니다.
예를 들어 주택의 20%가 size=medium and location=good이면 size=medium는 20% 이상이다.
Apriori 속성은 검사할 패턴의 수를 줄이는 데 사용됩니다.
패턴이 빈번한 경우에만 더 높은 순위의 패턴을 확인해야 합니다.
이제 베이지안 규칙 목록 알고리즘의 확인 전 조건을 완료했습니다. 하지만 BRL의 두 번째 단계로 넘어가기 전에 미리 확인된 패턴을 기반으로 규칙 학습을 위한 다른 방법을 알려드리고자 합니다. 다른 접근방식은 빈번한 패턴 확인 프로세스에 예측하고자하는 결과를 포함시키고 IF-THEN 규칙을 만드는 Apriori 알고리즘의 두 번째 부분을 실행하는 것을 제안합니다. 알고리즘이 비지도학습이기 때문에 THEN-Part에는 우리가 관심이 없는 특성 값도 포함되어 있습니다. 하지만 우리는 오직 예측하고자하는 결과만을 출력하도록 규칙에 따라 필터링할 수 있습니다. 이러한 규칙은 이미 결정 집합을 형성하지만 규칙을 정렬, 잘라내기, 삭제 또는 다시 결합할 수도 있습니다.
BRL 접근 방식에서는 빈번한 패턴으로 작업하며, THEN-부분을 배웁니다. 그리고 베이지안 통계를 사용하여 패턴을 의사결정 목록으로 배열하는 방법을 배웁니다.
베이지안 규칙 목록 학습
BRL 알고리즘의 목표는 미리 확인된 조건의 선택을 사용하여 정확한 의사결정 목록을 학습하는 동시에 규칙과 짧은 조건의 목록의 우선순위를 지정하는 것입니다. BRL은 조건의 길이(기본적으로 더 짧은 규칙) 및 규칙의 수(되도록 더 짧은 목록)에 대한 사전 분포와 함께 의사결정 목록의 분포를 정의하여 이 목표를 해결합니다.
목록의 사후 확률 분포를 사용하면 최적화의 가정과 그 목록이 데이터에 얼마나 잘 들어맞는지를 고려할 때 의사결정 목록이 얼마나 가능성이 있는지 말할 수 있습니다. 우리의 목표는 이 사후 확률을 극대화하는 목록을 찾는 것입니다. 목록의 분포에서 직접 가장 적합한 목록을 찾을 수 없으므로 BRL은 다음 방법을 제안합니다. 1) 사전 분포에서 무작위로 추출한 최초 의사결정 목록을 생성합니다. 2) 규칙을 추가, 전환 또는 제거하여 목록을 반복적으로 수정하고, 결과 목록이 목록의 사후 분포를 따르도록 합니다. 3) 사후 분포에 따라 확률이 가장 높은 샘플링된 목록에서 의사결정 목록을 선택합니다.
알고리즘에 대해 좀 더 자세히 살펴보겠습니다. 알고리즘은 FP-Growth 알고리즘을 사용하여 특성 값 패턴을 미리 확인하는 것으로 시작합니다. BRL은 대상의 분포와 대상의 분포를 정의하는 매개변수의 분포에 대해 여러 가지 가정을 합니다. (바로 베이지안 통계입니다.) 베이지안 통계에 익숙하지 않다면, 다음의 설명에 너무 얽매이지 마세요. 베이지안적 접근방식은 기존 지식이나 요구사항(소위 사전 분포)을 결합하는 동시에 데이터에 적합하다는 것을 아는 것이 중요합니다. 의사결정 목록의 경우, 이전의 가정은 의사결정 목록을 짧은 규칙으로 요약하기 때문에 베이지안 접근법이 타당합니다.
목표는 사후 분포에서 의사결정 목록 d를 샘플링하는 것입니다.
\[\underbrace{p(d|x,y,A,\alpha,\lambda,\eta)}_{posteriori}\propto\underbrace{p(y|x,d,\alpha)}_{likelihood}\cdot\underbrace{p(d|A,\lambda,\eta)}_{priori}\]여기서 d는 의사결정 목록, x는 특징, y는 대상, A는 미리 확인된 조건, \(\lambda\)는 의사결정 목록의 사전 예상 길이, \(\eta\)는 규칙의 사전 예상 조건 수, \(\alpha\)는 양수 및 음수 클래스에 대한 사전 임의의 카운트이다(주로 (1,1)로 고정함).
\[p(d|x,y,A,\alpha,\lambda,\eta)\]관측 데이터 및 사전 가정을 고려할 때 의사결정 목록의 개연성을 정량화합니다. 이는 의사결정 목록에 주어진 결과 y의 확률에 비례하며, 데이터는 주어진 사전 가정과 미리 확인된 조건의 목록 확률에 비례합니다.
\[p(y|x,d,\alpha)\]는 의사결정 목록과 데이터를 고려하여 관측된 y의 가능성입니다. BRL은 y가 Dirichlet-Multinomial 분포에 의해 생성된다고 가정합니다. 의사결정 목록 d가 데이터를 더 잘 설명할수록 가능성은 더 높아집니다.
\[p(d|A,\lambda,\eta)\]의사결정 목록의 사전 분포입니다. 목록의 규칙 수에 대한 truncated Poisson distribution(매개 변수 \(\lambda\))와 규칙 조건의 특성 값 수에 대한 truncated Poisson distribution(매개 변수 \(\eta\))를 곱하여 결합합니다.
의사결정 목록은 결과를 잘 설명하고 사전 가정에 따라 달라질 수 있는 높은 사후 확률을 가집니다.
베이지안 통계에서 추정치는 항상 약간 까다롭습니다. 왜냐하면 우리는 보통 정답을 직접 계산할 수는 없지만, 우리는 후보를 뽑고, 평가하고, 마르코프 체인 몬테 카를로 방법을 사용하여 사후 추정치를 업데이트해야 하기 때문입니다. 의사결정 목록의 경우, 의사결정 목록의 분포에서 도출해야 하기 때문에 훨씬 더 까다롭습니다. BRL 작성자는 먼저 초기 의사결정 목록을 작성한 다음 목록의 사후 분포(마코프 의사결정 목록 체인)에서 의사결정 목록 샘플을 생성하도록 반복적으로 수정할 것을 제안합니다. 결과는 초기 의사결정 목록에 따라 달라질 수 있으므로 다양한 목록을 만들려면 이 절차를 반복하는 것이 좋습니다. 소프트웨어 구현의 기본값은 10배입니다. 다음 방법은 초기 의사결정 목록을 작성하는 방법을 알려줍니다.
- FP-Growth로 패턴을 미리 파악합니다.
- Truncated Poisson distribution에서 목록 길이 매개변수 m을 샘플링합니다.
- 기본 규칙의 경우: 대상 값의 Dirichlet-Multinomial 분포 매개변수 $\theta_0$를 샘플링합니다(즉, 다른 규칙이 적용되지 않을 때 적용되는 규칙).
- 의사결정 목록 규칙 j=1,…,m은 다음을 수행합니다.
- 규칙 j의 규칙 길이 매개변수 l(조건 수)을 샘플링합니다.
- 미리 확인된 조건으로부터 \(l_j\) 길이의 조건을 샘플링합니다.
- THEN 파트의 Dirichlet-Multinomial 분포 파라미터를 샘플링합니다(즉, 규칙이 지정된 목표 결과의 분포).
- 데이터 집합의 각 관측치에 대해 다음을 수행합니다.
- 먼저 적용되는 의사결정 목록에서 규칙을 찾습니다(위부터 아래까지).
- 적용되는 규칙에 의해 제안된 확률 분포(이항 분포)에서 예측된 결과를 그립니다.
다음 단계는 이 초기 샘플부터 많은 새 목록을 생성하여 의사결정 목록의 사후 분포에서 많은 샘플을 획득하는 것입니다.
새 의사결정 목록은 처음 목록에서 시작한 다음 무작위로 규칙을 목록의 다른 위치로 이동하거나 미리 마이닝된 조건에서 현재 의사결정 목록에 규칙을 추가하거나 의사결정 목록에서 규칙을 제거하여 샘플링됩니다. 전환, 추가 또는 삭제되는 규칙 중 임의로 선택되는 규칙이 있습니다. 각 단계에서 알고리즘은 의사결정 목록의 후연 확률을 평가합니다(정확성과 단축을 같이 고려). Metropolis Hastings 알고리즘을 사용하면 사후확률이 높은 의사결정 목록을 샘플링할 수 있습니다. 이 절차는 의사결정 목록의 분포에서 얻은 많은 샘플을 제공합니다. BRL 알고리즘은 사후 확률이 가장 높은 표본의 의사결정 목록을 선택합니다.
예시
이론은 여기까지입니다. 이제 BRL 방법을 실행해 보겠습니다. 이 예에서는 Yang et al. (2017)5의 SBRL(Scalable Bayesian Rule Lists)이라는 BRL의 더 빠른 변형을 사용합니다. SBRL 알고리즘을 사용하여 자주경부암에 대한 위험을 예측합니다. 먼저 SBRL 알고리즘의 모든 입력 특성을 해제해야 했습니다. 이를 위해 정량형별 값의 빈도를 기준으로 연속 특성을 빈도로 처리했습니다.
다음과 같은 규칙이 적용됩니다.
| rules |
|---|
| If {STDs=1} (rule[259]) then positive probability = 0.16049383 |
| else if {Hormonal.Contraceptives..years.=[0,10)} (rule[82]) then positive probability = 0.04685408 |
| else (default rule) then positive probability = 0.27777778 |
참고로 우리는 합리적인 규칙을 얻습니다. 왜냐하면 그 예측은 클래스의 결과가 아니라 암에 대한 예측 확률이기 때문입니다.
조건은 FP-Growth 알고리즘으로 미리 확인한 패턴에서 선택되었습니다. 다음 표에는 SBRL 알고리즘이 의사결정 목록을 작성하기 위해 선택할 수 있는 조건들이 입니다. 허용한 조건의 최대 특성 값 수는 2개입니다. 다음은 10가지 패턴의 샘플입니다.
| pre-mined conditions |
|---|
| Num.of.pregnancies=[3.67,7.33) |
| IUD=0,STDs=1 |
| Number.of.sexual.partners=[1,10),STDs..Time.since.last.diagnosis=[1,8) |
| First.sexual.intercourse=[10,17.3),STDs=0 |
| Smokes=1,IUD..years.=[0,6.33) |
| Hormonal.Contraceptives..years.=[10,20),STDs..Number.of.diagnosis=[0,1) |
| Age=[13,36.7) |
| Hormonal.Contraceptives=1,STDs..Number.of.diagnosis=[0,1) |
| Number.of.sexual.partners=[1,10),STDs..number.=[0,1.33) |
| STDs..number.=[1.33,2.67),STDs..Time.since.first.diagnosis=[1,8) |
다음으로 자전거 대여 예측 문제에 SBRL 알고리즘을 적용합니다. 이 특성은 자전거 수 예측의 회귀 문제가 이진 분류 작업으로 변환된 경우에만 작동합니다. 저는 임의로 자전거의 수가 하루에 4,000 대를 초과할 경우 1, 그렇지 않으면 0이라는 분류 문제를 만들었습니다.
다음 목록은 SBRL로 학습한 결과입니다.
| rules |
|---|
| If {yr=2011,temp=[-5.22,7.35)} (rule[718]) then positive probability = 0.01041667 |
| else if {yr=2012,temp=[7.35,19.9)} (rule[823]) then positive probability = 0.88125000 |
| else if {yr=2012,temp=[19.9,32.5]} (rule[816]) then positive probability = 0.99253731 |
| else if {season=SPRING} (rule[351]) then positive probability = 0.06410256 |
| else if {yr=2011,temp=[7.35,19.9)} (rule[730]) then positive probability = 0.44444444 |
| else (default rule) then positive probability = 0.79746835 |
2012년 하루 동안 자전거의 수가 섭씨 17도의 온도에서 4,000 대를 넘어설 확률을 예측해 보겠습니다. 첫 번째 규칙은 2011년 며칠 동안만 적용되므로 적용되지 않습니다. 두 번째 규칙은 2012년이고 17도가 “[7.35,19.9)” 간격이기 때문에 적용됩니다. 4,000 대 이상의 자전거가 임차될 가능성이 88%라고 예측하고 있습니다.
장점
IF-THEN 규칙의 이점에 대해 설명해보겠습니다.
IF-THEN 규칙은 해석하기 쉽습니다. 해석 가능한 모델 중 가장 해석 가능한 모델일 수 있습니다. 이 문장은 규칙 수가 적거나, 규칙 조건이 짧거나(최대 3개) 규칙이 의사결정 목록 또는 중복되지 않은 결정 집합으로 구성된 경우에만 적용됩니다.
의사결정 규칙은 의사결정 트리로서 표현 가능한 반면, 보다 간결한 방법일 수 있습니다. 의사결정 트리는 생성된 하위 트리, 즉 왼쪽 노드와 오른쪽 하위 노드의 분할이 동일한 구조로 인해 종종 어려움을 겪습니다.
적용되는 규칙을 결정하려면 몇 개의 이진 문만 확인하면 되므로 IF-THEN 규칙이 포함된 예측 속도는 빠릅니다.
조건의 임계값만 변경되므로 입력 특성의 단조로운 변환에 대한 의사 결정 규칙은 강건합니다. 또한 조건이 적용되는 경우에만 문제가 되기 때문에 이상치에 대해서도 강합니다.
IF-THEN 규칙은 일반적으로 sparse한 모형을 생성하므로 많은 특성이 포함되지 않습니다. 모델에 대해 관련 특성만 선택합니다. 예를 들어 선형 모델은 기본적으로 모든 입력 특성에 가중치를 할당합니다. IF-THEN 규칙에서는 관련이 없는 특성은 무시될 수 있습니다.
OneR 과 같은 간단한 규칙은 보다 복잡한 알고리즘을 위해 기준선으로 사용할 수 있습니다.
단점
IF-THEN 규칙의 단점을 다뤄봅시다.
IF-THEN 규칙에 대한 연구 및 문헌은 분류에 초점을 맞추고 있으며 거의 회귀를 완전히 무시합니다. 연속 대상을 항상 간격으로 분할하여 분류 문제로 전환할 수 있지만 항상 정보가 손실됩니다. 일반적으로 회귀 분석과 분류에 모두 사용할 수 있는 접근법이 더 매력적입니다.
특성도 범주형이어야 하는 경우가 많습니다. 즉, 숫자 특성를 사용하려면 해당 특성를 분류해야 합니다. 연속적인 특성을 간격으로 자르는 방법은 여러 가지가 있지만, 이는 사소한 것이 아니며 명확한 대답 없이 많은 의문점이 수반됩니다. 특성을 몇 개의 간격으로 분할해야 하는가? 분할 기준은 무엇인가? 고정 간격 길이, 정량형 또는 다른 것 중 어떤 것이 있는가? 연속 특성을 분류하는 것은 종종 무시되는 비개인적인 문제이며, 사람들은 그저 차선책을 사용합니다(예에서 그랬던 것처럼).
대부분 오래된 규칙 학습 알고리즘은 지나치게 적합하기 쉽습니다. 여기에 제시된 알고리즘에는 모두 과적합을 방지하기 위한 몇 가지 안전 장치가 있습니다. OneR은 하나의 특성만 사용할 수 있기 때문에 제한됩니다(특성의 레벨이 너무 많거나 다중 테스트 문제와 같은 특성이 많은 경우에만 문제됨). RIPPER는 잘라내기를 수행하고 Bayesian Rule Lists는 의사결정 목록에 사전 분포를 적용합니다.
의사 결정 규칙은 특성와 출력 간의 선형 관계를 설명하는 데 좋지 않습니다. 이는 의사결정 트리와 같은 문제입니다. 의사결정 트리 및 규칙은 단계별 예측 특성만 생성할 수 있으며, 예측의 변경은 항상 별개의 단계이며 결코 매끄러운 곡선을 형성하지 않습니다. 이는 입력이 범주형이어야 하는 문제와 관련이 있습니다. 의사결정 트리에서는 이를 분할하여 암묵적으로 분류합니다.
소프트웨어 및 대체방법
이 책의 예에 사용된 OneR은 R 패키지 OneR에 구현되어 있습니다. OneR은 Weka 머신러닝 라이브러리에서도 구현되어 있습니다. RIPPER는 Weka에서도 구현됩니다. 예를 들면, RWeka package)에서 JRIP의 R 구현을 이용했습니다. SBRL은 R package(예시에서 사용함), Python 또는 C 구현체으로 제공됩니다.
저는 의사결정 규칙 집합과 목록을 배울 수 있는 모든 대안들을 나열하지 않고, 몇 가지만 요약했습니다. Fuernkranz의 책 “Foundations of Rule Learning”(2012)6을 추천합니다. 이 책은 이 주제에 대해 더 깊이 파고들기를 원하는 사람들을 위해 학습 규칙에 관한 광범위한 연구에 대한 내용입니다. 학습 규칙을 생각하기 위한 전체론적 프레임워크를 제공하고 많은 규칙 학습 알고리즘을 제시합니다. Weka 규칙 학습자도 확인할 것을 권장합니다. RIPPER, M5Rules, OneR, PART 등 구현되어 있습니다. IF-THEN 규칙은 RuleFit 알고리즘에 대한 장에 설명된 대로 선형 모형에서 사용할 수 있습니다.
-
Holte, Robert C. “Very simple classification rules perform well on most commonly used datasets.” Machine learning 11.1 (1993): 63-90. ↩
-
Cohen, William W. “Fast effective rule induction.” Machine Learning Proceedings (1995). 115-123. ↩
-
Letham, Benjamin, et al. “Interpretable classifiers using rules and Bayesian analysis: Building a better stroke prediction model.” The Annals of Applied Statistics 9.3 (2015): 1350-1371. ↩
-
Borgelt, C. “An implementation of the FP-growth algorithm.” Proceedings of the 1st International Workshop on Open Source Data Mining Frequent Pattern Mining Implementations - OSDM ’05, 1–5. http://doi.org/10.1145/1133905.1133907 (2005). ↩
-
Yang, Hongyu, Cynthia Rudin, and Margo Seltzer. “Scalable Bayesian rule lists.” Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017. ↩
-
Fürnkranz, Johannes, Dragan Gamberger, and Nada Lavrač. “Foundations of rule learning.” Springer Science & Business Media, (2012). ↩