1.3 Terminology
애매함때문에 혼란이 생기는 것을 피하기위해 책에서 사용되는 몇가지 단어들에 대해 정의하고 넘어가도록 합니다.
알고리즘(Algorithm)은 기계가 특정 목적을 달성하기위해 따르는 규칙을 말합니다1. 알고리즘은 입력값, 출력값 그리고 입력으로부터 결과를 얻기까지의 모든 단계들이 담겨있는 레시피로 생각해볼 수도 있습니다. 요리 레시피는 재료가 입력값, 요리한 음식이 출력값 그리고 준비와 요리 과정이 알고리즘의 지침서라고 생각할 수 있습니다.
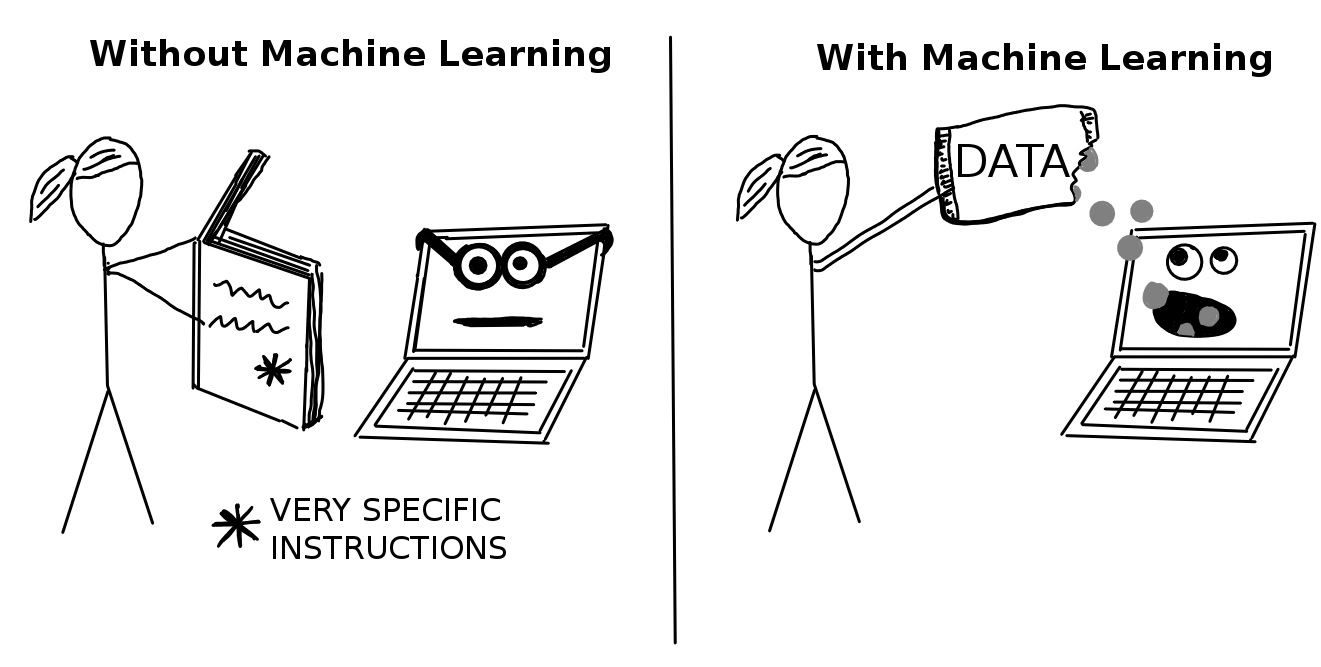
머신러닝(Machine Learning)은 컴퓨터가 데이터로부터 예측치(예를 들면 암, 주간 판매량, 신용 부도)를 만들고 개선할 수 있게 하는 방법입니다. 머신러닝은 모든 지침서를 컴퓨터에게 제공해야했던 “normal programming”에서 데이터를 제공함으로서 발생되는 “indirect programming”으로 패러다임을 바꿨습니다.
학습기(Learner) 또는 머신러닝 알고리즘(Machine Learning Algorithm)은 머신러닝 모델이 데이터를 학습하기 위해 사용되는 프로그램을 말합니다. 또다른 이름은 “유도기(inducer)”입니다. (e.g “tree inducer”)
머신러닝 모델(Machine Learning Model)은 입력값과 예측치를 매칭하는 학습된 프로그램입니다. 선형 모델이나 신경망에서 가중치와 같은 것들을 말합니다. 모델이라고 하면 약간 애매할 수 있어서 또 다른 이름으로는 “예측기(predictor)” 또는 문제에 따라 “분류기(classifier)” 또는 “회귀 모델(regression model)”이라고도 말합니다. 수식적으로는 학습된 머신러닝 모델을 \(\hat{f}\) 또는 \(\hat{f}(x)\)으로 나타냅니다.
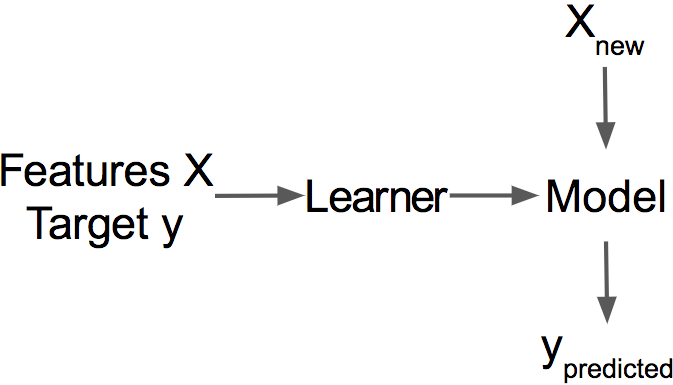
그림 1.1: 학습기는 정답이 있는 훈련 데이터를 통해 모델을 학습합니다. 그리고 모델은 예측값을 만들어냅니다.
학습기는 정답이 있는 학습 데이터로부터 모델을 학습하고 학습된 모델은 예측치을 만들어냅니다.
블랙 박스 모델(Black Box Model)은 내부 매커니즘을 드러낼 수 없는 시스템을 말합니다. 머신러닝에서 “블랙 박스”는 신경망같은 모델의 파라미터를 봐도 이해할 수 없는 모델을 말합니다. 블랙박스의 반대말로는 “화이트박스(White Box)”라고도 합니다. 이 책에서는 interpretable model이라고 얘기합니다. 해석가능성을 위한 Model-agnostic 방법들은 모든 머신러닝 모델을 블랙박스로 바라봅니다.

해석가능한 기계 학습(Interpretable Machine Learning)은 머신러닝 모델의 패턴과 예측치를 사람이 이해할 수 있도록 만드는 것을 말합니다.
데이터셋(Dataset)은 기계가 학습할 데이터가 있는 테이블입니다. 데이터셋에는 특성들과 예측을 위한 목표값이 있습니다. 모델에 사용될때는 데이터셋을 학습데이터라고 부릅니다.
사례(Instance)는 데이터셋에서 행에 해당합니다. 또 다른 이름은 (데이터) 포인트(point), 예제(example), 관측치(observation) 입니다. (변역본에서는 instance를 모두 관측치로 하였습니다.) 관측치는 특성값 \(x^(i)\)과 알려져있는 경우 목표값인 \(y_i\)로 구성되어 있습니다.
특성(Features)은 예측 또는 분류를 위해 사용되는 입력값입니다. 특성은 데이터셋에서 각 열에 해당합니다. 이 책에서 특성은 해석가능한 것으로 가정하는데 이는 주어진 날의 온도나 사람의 키와 같이 각각이 의미하는 바를 이해하기 쉽다는 것을 말합니다. 특성의 해석가능성은 중요한 가정입니다. 이 가정없이 모델의 패턴을 이해하는 것은 어렵습니다. 모든 특성들의 행렬은 \(X\)이고 각 관측치에 대해서는 \(x^(i)\)입니다. 모든 관측치에 대해 각 특성 벡터는 \(x_j\)이고 특성 \(j\)와 관측치 \(i\)는 \(x^(i)_j\)입니다.
목표값(Target)은 기계가 예측을 위해 학습해야할 정보입니다. 수학적 수식으로 목표값은 보통 각 관측치에 대해서 \(y\)나 \(y_i\)로 나타냅니다.
머신러닝 문제(Machine Learning Task)는 특성과 목표값이 있는 데이터셋의 조합입니다. 목표값의 유형에 따라 문제는 분류, 회귀, 생존 분석, 군집화 또는 이상치 탐지가 될 수 있습니다.
예측치(Prediction)는 주어진 특성을 기반으로 목표값이 무엇인지 머신러닝 모델의 “추측(guesse)”입니다. 이 책에 모델 예측치는 \(\hat{f}(x^(i))\) 또는 \(\hat{y}\)로 표기합니다.
-
“Definition of Algorithm.” https://www.merriam-webster.com/dictionary/algorithm. (2017). ↩