Chapter 5. Model-Agnostic Methods
Model-Agnostic Methods
머신러닝 모델(= model-agnostic interpretation methods)과 설명을 구분하면 몇 가지 장점이 있습니다(Ribeiro, Singh, and Guestrin 20161). 모델별 해석 방법보다 모델별 해석 방법이 갖는 큰 장점은 유연성입니다. 머신러닝 개발자는 해석 방법을 모든 모델에 적용할 수 있을 때 원하는 머신러닝 모델을 자유롭게 사용할 수 있습니다. 그래픽 또는 사용자 인터페이스와 같은 머신러닝 모델의 해석에 기초하는 모든 것은 기본 머신러닝 모델과 독립적입니다. 일반적으로 한 가지뿐 아니라 여러 가지 유형의 머신러닝 모델을 평가하여 문제를 해결하며, 해석 가능성 측면에서 모델을 비교할 때 어떤 유형의 모델에도 동일한 방법을 사용할 수 있기 때문에 모델에 구애받지 않는 설명으로 작업하기가 더 쉽습니다.
모델에 구애받지 않는 해석 방법의 대안은 해석 가능한 모델만 사용하는 것입니다. 이는 종종 다른 머신러닝 모델에 비해 예측 성능이 저하되고 한 유형의 모델로 제한된다는 단점이 큽니다. 다른 대안은 모델별 해석 방법을 사용하는 것입니다. 이 기능의 단점은 또한 한 모델 유형에 구속되며 다른 모델 유형으로 전환하기 어렵다는 점입니다.
모델과 무관한 설명 시스템의 바람직한 측면은 (Ribeiro, Singh, and Guestrin 2016)입니다.
- 모델 유연성(model flexibility): 해석 방법은 임의의 숲이나 깊은 신경망과 같은 모든 머신러닝 모델과 함께 사용할 수 있습니다.
- 설명 유연성(explanation flexibility): 여러분은 특정한 형태의 설명에만 국한되지 않습니다. 경우에 따라 선형 공식을 사용하는 것이 유용할 수 있으며, 다른 경우에는 특성 중요도가 있는 그래프를 사용하는 것이 유용할 수 있습니다.
- 표현 유연성(representation flexibility): 설명 시스템은 설명 중인 모델과 다른 특성 표현을 사용할 수 있어야 합니다. 단어 임베딩 벡터를 사용하는 텍스트 분류기의 경우 설명을 위해 개별 단어의 존재를 사용하는 것이 좋습니다.
큰 그림
모델에 구애받지 않는 해석성에 대해 자세히 살펴보겠습니다. 우리는 데이터를 수집하고, 머신러닝 모델을 통해 데이터를 예측하는 방법을 학습함으로써 세계를 요약합니다. 해석성은 인간이 이해할 수 있도록 돕는 또 다른 층에 불과합니다.
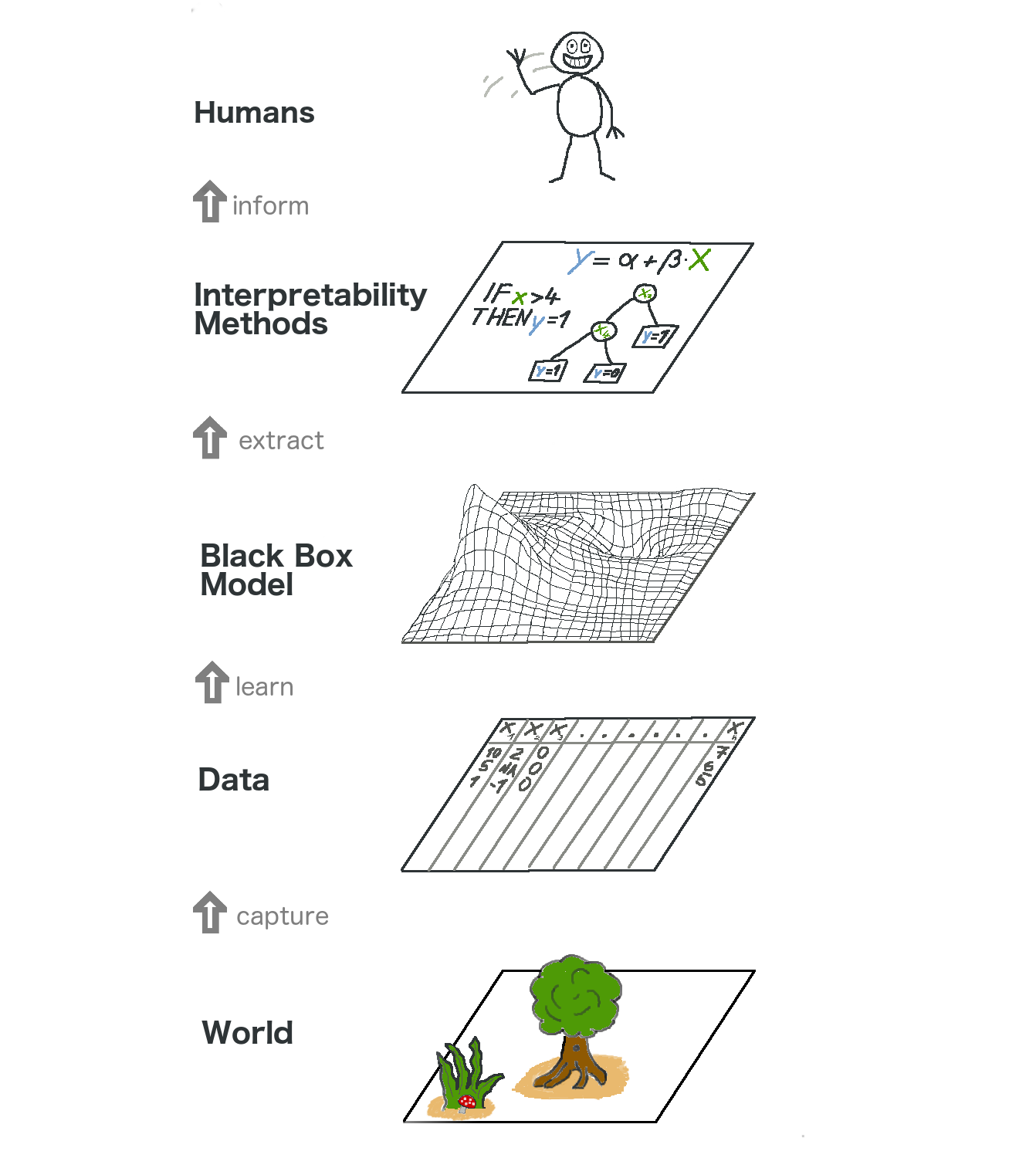
그림 5.1: 설명 가능한 머신러닝의 큰 그림입니다. 실제 세계는 설명의 형태로 인간에게 도달하기 전에 많은 층을 거칩니다.
가장 낮은 계층은 World입니다. 이것은 말 그대로 자연 그 자체일 수 있습니다. 인체의 생물학적, 약물에 어떻게 반응하는지와 같은 것이죠. 또한 부동산 시장처럼 더 추상적인 것들이죠. World 레이어에는 관찰할 수 있고 관심 있는 모든 것이 포함되어 있습니다. 궁극적으로, 우리는 세계에 대해 배우고 싶고, 세상과 교류하고 싶습니다.
두 번째 레이어는 Data 레이어입니다. 우리는 컴퓨터를 통해 처리하고 정보를 저장하기 위해 세상을 디지털화해야 합니다. Data 계층에는 이미지, 텍스트, 표 형식의 데이터 등이 포함됩니다.
데이터 계층에 기반한 머신러닝 모델을 장착함으로써 Black Box Model 계층을 얻을 수 있습니다. 머신러닝 알고리즘은 예측을 하거나 구조를 찾기 위해 실제 데이터를 사용하여 학습합니다.
Black Box Model 레이어 위에는 머신러닝 모델의 불투명성을 처리하는 데 도움이 되는 interprapeability Methods 레이어가 있습니다. 특정 진단에 가장 중요한 기능은 무엇입니까? 왜 금융거래가 사기로 분류되었습니까?
마지막 레이어는 Human이 차지하고 있습니다. 보세요! 여러분이 이 책을 읽고 있고 블랙박스 모델에 대한 더 나은 설명을 제공하도록 돕기 때문에 여러분에게 손을 흔드는 거예요! 인간은 결국 그 설명의 소비자입니다.
이 다중 계층 요약은 통계학자와 머신러닝 실무자 사이의 접근 방식의 차이를 이해하는 데에도 도움이 됩니다. 통계학자는 임상 시험 계획 또는 설문 조사 설계와 같은 데이터 계층을 다룹니다. 블랙 박스 모델 계층을 건너뛰고 해석 방법 계층으로 바로 이동합니다. 머신러닝 전문가들은 또한 피부암 이미지의 표본을 수집하거나 위키피디아 데이터를 가져오는 것과 같은 데이터 계층을 다루고 있습니다. 그런 다음 블랙박스 머신러닝 모델을 교육합니다. 해석 방법 계층은 건너뛰고 인간은 블랙 박스 모델 예측을 직접 처리합니다. 해석 가능한 머신러닝이 통계학자와 머신러닝 전문가의 작업을 융합시킨다는 것은 대단한 일입니다.
물론 이 그래프가 모든 것을 담고 있는 것은 아닙니다. 시뮬레이션으로도 데이터를 모을 수 있습니다. 블랙박스 모델들은 또한 인간에게 도달하지도 않고 다른 기계만을 공급하는 예측을 출력합니다. 그러나 전체적으로 해석성이 어떻게 머신러닝 모델 위에 새로운 계층이 되는지를 이해하는 것은 유용한 요약본입니다.
-
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Model-agnostic interpretability of machine learning.” ICML Workshop on Human Interpretability in Machine Learning. (2016). ↩