Shapley Values
Shapley value
예측이 지불금(payout)인 게임에서는 관측치의 각 특성값이 “선수(player)”라고 가정하여 예측을 설명할 수 있습니다. Shapley value는, 협동 게임 이론(coalitional game theory)의 한 방법으로서, 특성들 간에 “지불금”을 공평하게 분배하는 방법을 알려줍니다.
아이디어
다음과 같은 시나리오를 가정합니다.
당신은 아파트 가격을 예측하기 위해 머신러닝 모델을 학습했습니다. 특정 아파트의 경우 €300,000를 예상하며 이 예측을 설명해야 합니다. 아파트의 크기는 \(50m^2\)이며, 근처에 공원이 있고 고양이는 금지되어 있습니다.
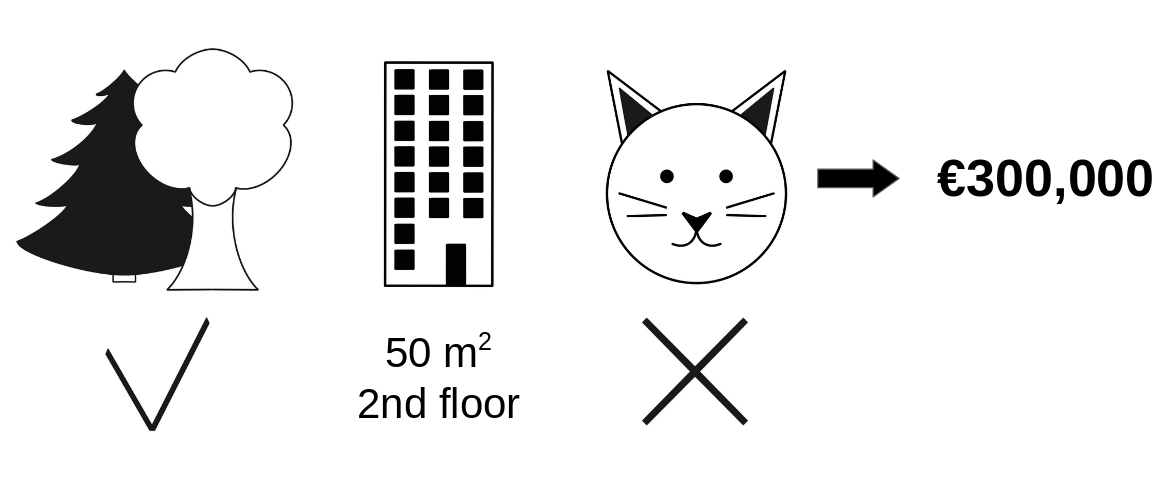
그림 5.43: 근처 공원과 고양이 금지 구역인 $$50m^2$$ 2층 아파트의 예상 가격은 €300,000입니다. 우리의 목표는 이러한 각각의 특성적 가치들이 어떻게 예측에 기여했는지를 설명하는 것입니다.
모든 아파트의 평균 가격은 310,000유로에 달합니다. 각 특성값이 평균 예측과 비교하여 예측에 얼마나 기여하였을까요?
선형 회귀 모델의 경우 간단하게 답을 내릴 수 입니다. 각 특성의 효과는 특성의 값의 가중치 입니다. 이것은 모델의 직선성 때문에만 효과가 있습니다. 좀 더 복잡한 모델의 경우, 우리는 다른 해결책이 필요합니다. 예를 들어, LIME은 효과를 추정하기 위해 local 모델을 제안합니다. 또 다른 해결책은 협동 게임 이론입니다. Shapley(1953년)1가 만든 shapley value는 총 지불금에 대한 기여도에 따라 선수에게 지불금을 배분하는 방법입니다. 선수들은 협동에 협력하고 이 협력으로 일정한 이익을 얻습니다.
선수들?
게임?
지불금?
머신러닝 예측과 해석 가능성과의 연관성은 무엇일까요?
“게임”은 데이터 세트의 단일 관측치에 대한 예측 작업입니다.
“이득(gain)”은 이 경우에 대한 실제 예측에서 모든 경우의 평균 예측을 뺀 것입니다.
“선수”는 이득을 얻기 위해 협력하는 관측치의 특성값입니다(= 특정 값을 예측).
우리 아파트 사례에서는 park-nearby, cat-banned, area-50, floor-2nd의 특성 값들이 함께 작용해 €300,000의 예측을 만들었습니다.
우리의 목표는 실제 예측(유로 €300,000)과 평균 예측(€310,000)의 차이를 설명하는 것입니다.
답은 다음과 같습니다.
park-nearby는 €30,000, area-50은 €10,000, floor-2nd는 €0, cat-banned은 €50,000 였습니다.
기여도은 €-10,000, 최종 예측에서 평균 아파트 가격을 뺀 것입니다.
한 특성에 대한 shapley value는 어떻게 계산하는가?
shapley value는 가능한 모든 연합에서 특성 값의 평균 한계 기여 값입니다. 이제 끝 일까요?
다음 그림에서 우리는 park-nearby와 area-50의 연합에 cat-banned 특성의 가치를 더했을 때 그 기여도를 평가합니다.
우리는 자료에서 임의로 다른 아파트를 선택하여 그 값을 바닥 특성에 이용함으로써 단지 park-nearby, cat-banned, area-50만이 연합하고 있는 것으로 시뮬레이션합니다.
floor-2nd은 무작위로 추출한 floor-1nd으로 대체됐습니다.
그런 다음 이 조합으로 아파트 가격을 예측합니다(310,000유로).
두 번째 단계에서는 무작위로 추출한 아파트에서 cat allowed/banned 특성의 무작위 값으로 대체하여 연합에서 cat-banned를 제거합니다.
예에서 cat-allowed이었지만 다시 cat-banned이 될 수도 있습니다.
park-nearby와 area-50(€320,000)의 연합 아파트가격을 전망합니다.
cat-banned의 기여도는 €310,000~€320,000= -€10.000 입니다.
이 추정치는 무작위로 추출한 고양이와 바닥 특성 값의 “기부자(donor)” 역할을 한 아파트 값에 따라 달라집니다.
우리가 이 샘플링 단계를 반복하고 기여도를 평균낸다면 우리는 더 나은 추정치를 얻을 것입니다.
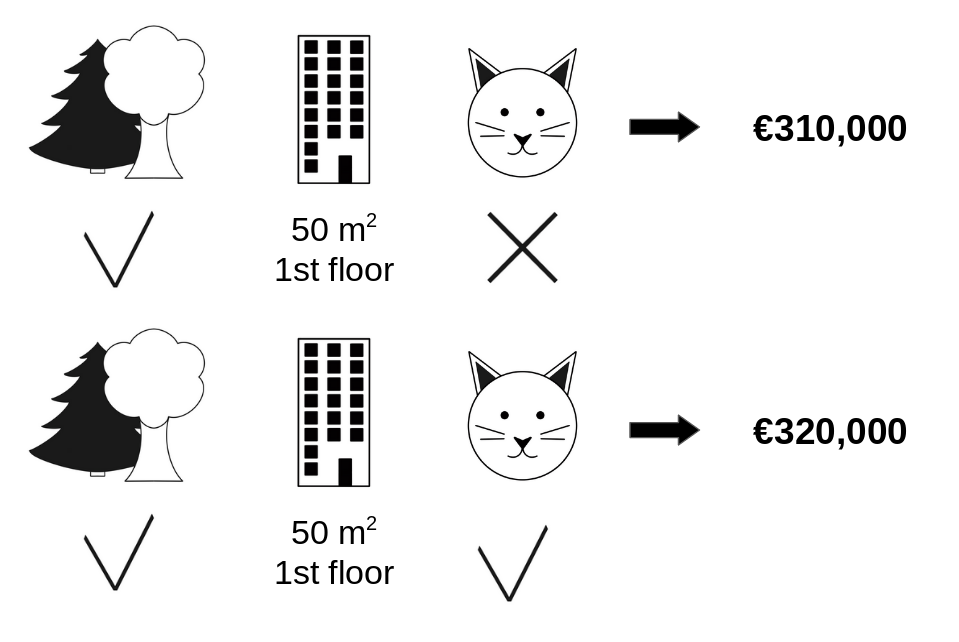
그림 5.44: `park-nearby`와 `area-50`의 연합에 더해 예측에 `cat-banned`의 기여도를 추정하기 위한 하나의 표본 반복입니다.
우리는 가능한 모든 협동에 대해 이 계산을 반복합니다. shapley value는 가능한 모든 협동에 대한 모든 한계 기여도(marginal contributions)의 평균입니다. 연산 시간은 특성의 수에 따라 기하급수적으로 증가합니다. 계산 시간을 관리 가능한 상태로 유지하는 한 가지 해결책은 가능한 연합의 몇 가지 샘플에 대한 기여도를 계산하는 것입니다.
다음 그림은 cat-banned의 shapley value를 결정하는 데 필요한 특성값의 모든 연합을 보여줍니다.
첫 번째 행은 특성값 없는 협동을 보여줍니다.
두 번째, 세 번째, 네 번째 행은 \(\shortmid\)로 구분된, 점점 커지는 연합 규모를 가진 다른 연합을 보여줍니다.
대체로 다음과 같은 협동이 가능합니다.
No feature valuespark-nearbysize-50floor-2ndpark-nearby+size-50park-nearby+floor-2ndsize-50+floor-2ndpark-nearby+size-50+floor-2nd.
이러한 각각의 연합주택에 대해 우리는 특성 값인 cat-banned가 있든 없든 예측 아파트 가격을 계산하고 그 차액을 취하여 한계 기여도를 얻습니다.
Shapley value는 한계 기여도의 (가중치) 평균입니다.
우리는 머신러닝 모델에서 예측을 얻기 위해 연합에 포함되지 않은 특성의 특성 값을 아파트 데이터 세트의 무작위 특성 값으로 대체합니다.
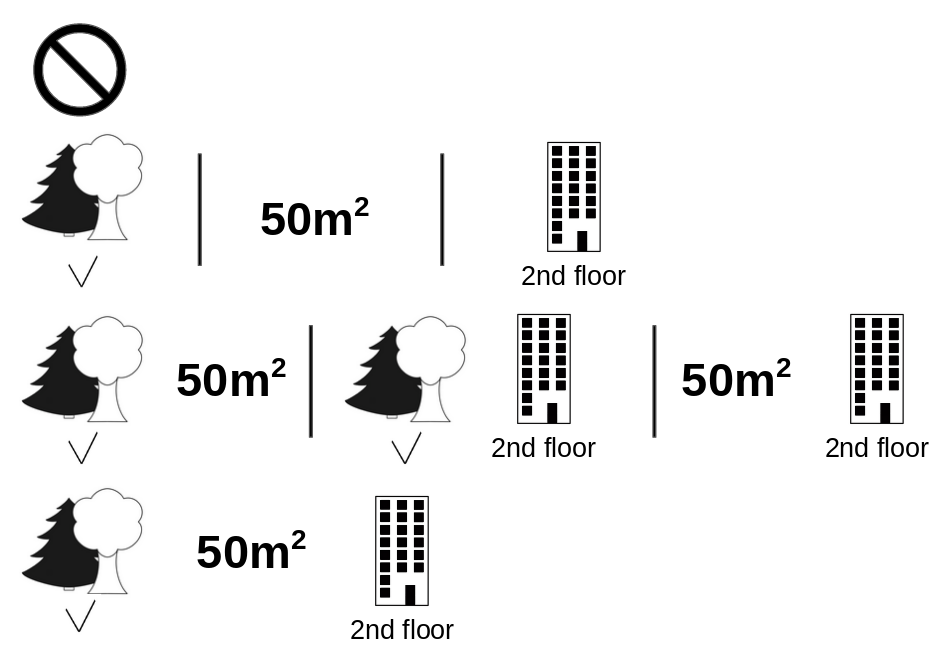
그림 5.45: 8개의 연탄은 모두 `cat-banned` 특성 값의 shapley value를 정확히 계산하는 데 필요합니다.
모든 특성 값에 대해 shapley value를 추정하면 특성 값 중 예측값의 전체 분포(평균값 제외)를 얻습니다.
예시 및 해석
특성값 j에 대한 shapley value의 해석은 다음과 같습니다. j번째 특성의 값은 데이터 세트의 평균 예측과 비교하여 이 특정 관측치의 예측에 \(\phi_j\)을(를) 기여했습니다.
shapley value는 분류(확률을 다루는 경우)와 회귀에 모두 적용됩니다.
우리는 shapley value를 사용하여 자궁경부암을 예측하는 랜덤 포레스트 모델의 예측을 분석합니다.

그림 5.46: 자궁경부암 데이터 세트에 있는 여성에 대한 shapley value. 0.57의 예측으로 이 여성의 암 발생 확률은 평균 예측치보다 0.03 더 높은 0.54입니다. 진단된 성병의 수는 그 확률을 가장 많이 증가시켰습니다
. 기여도 합계는 실제 예측과 평균 예측(0.54)의 차이를 산출합니다.
자전거 대여 데이터셋의 경우, 날씨와 날짜 정보를 고려하여 하루 동안 대여한 자전거의 수를 예측하는 랜덤 포레스트를 훈련합니다. 특정 요일의 랜덤 포레스트 예측을 위해 작성된 설명:

그림 5.47: 날짜에 대한 shapley value는 285입니다. 2409대의 대여 자전거가 예상돼 이날은 평균 예상인 4518대보다 -2108대 낮았습니다. 기상 상황과 습도, 부정적 영향이 가장 컸습니다. 이날 기온은 긍정적인 기여를 했습니다. shapley value의 합은 실제와 평균 예측의 차이를 산출합니다(-2108).
shapley value를 올바르게 해석하도록 주의해야합니다. shapley value는 서로 다른 연합에서 계산된 예측에 대한 특성값의 평균 기여 값입니다. shapley value는 모델에서 특성을 제거할 시점의 예측값에 대한 차이가 아닙니다.
The Shapley Value in Detail
이 절은 호기심 많은 독자를 위한 shapley value의 정의와 계산에 더 깊이 다룹니다. 기술 세부 사항에 관심이 없는 경우 이 절을 건너뛰고 “장점과 단점”으로 바로 이동하셔도 됩니다.
우리는 각 특성이 데이터의 예측에 어떻게 영향을 미치는지 관심이 있습니다. 선형 모델에서는 개별 효과를 계산하기 쉽습니다. 하나의 데이터 관측치에 대한 선형 모델 예측은 다음과 같습니다.
\[\hat{f}(x)=\beta_0+\beta_{1}x_{1}+\ldots+\beta_{p}x_{p}\]여기서 x는 기여를 계산하려는 관측치입니다. 각 \(x_j\)는 특성 값이며, j = 1,…,p입니다. \(\beta_j\)는 특성 j에 해당하는 중량입니다.
예측 \(\hat{f}(x)\)에 대한 j번째 특성의 기여 \(\phi_j\):
\[\phi_j(\hat{f})=\beta_{j}x_j-E(\beta_{j}X_{j})=\beta_{j}x_j-\beta_{j}E(X_{j})\]여기서 \(E(\beta_jX_{j})\)는 특성 j에 대한 평균 효과 추정치입니다. 기여도는 특성 효과에서 평균 효과를 뺀 값입니다. 굳! 이제 우리는 각각의 특성이 예측에 얼마나 기여했는지 알 수 있습니다. 한 관측치에 대한 모든 특성의 기여도를 합산하면 그 결과는 다음과 같습니다.
\[\begin{align*}\sum_{j=1}^{p}\phi_j(\hat{f})=&\sum_{j=1}^p(\beta_{j}x_j-E(\beta_{j}X_{j}))\\=&(\beta_0+\sum_{j=1}^p\beta_{j}x_j)-(\beta_0+\sum_{j=1}^{p}E(\beta_{j}X_{j}))\\=&\hat{f}(x)-E(\hat{f}(X))\end{align*}\]이것은 데이터 포인트 x에서 평균 예측값을 뺀 값입니다. 특성의 기여도는 음수가 될 수 있습니다.
다른 종류의 모델에도 똑같이 할 수 있을까요? 이것을 model-agnostic 도구로 사용할 수 있으면 좋을 것입니다. 우리는 보통 다른 모델 유형에서 비슷한 가중치를 가지고 있지 않기 때문에 다른 해결책이 필요합니다.
도움은 다음과 같이 예상치 못한 곳에서 옵니다. 협동 게임 이론. Shapley value는 모든 머신러닝 모델에 대한 단일 예측에 대한 특성의 기여도를 계산하는 솔루션입니다.
The Shapley Value
Shapley value는 S의 선수 값 함수 값을 통해 정의됩니다.
특성값의 shapley value는 가능한 모든 특성값 조합에 대해 가중치 부여 및 합산된 지불금에 대한 기여도입니다.
\[\phi_j(val)=\sum_{S\subseteq\{x_{1},\ldots,x_{p}\}\setminus\{x_j\}}\frac{|S|!\left(p-|S|-1\right)!}{p!}\left(val\left(S\cup\{x_j\}\right)-val(S)\right)\]여기서 S는 모델에 사용되는 특성의 부분집합이며, x는 설명할 관측치의 특성값의 벡터이고, p는 특성의 수입니다. \(val_x(S)\)는 세트 S에 포함되지 않은 특성보다 한계화된 집합 S의 특성 값에 대한 예측입니다.
\[val_{x}(S)=\int\hat{f}(x_{1},\ldots,x_{p})d\mathbb{P}_{x\notin{}S}-E_X(\hat{f}(X))\]실제로 S가 포함되지 않은 각 특성에 대해 여러 적분을 수행합니다. 구체적인 예: 머신러닝 모델은 4가지 특성 x1, x2, x3 및 x4로 작동하며, 특성 값 x1과 x3으로 구성된 연합 S에 대한 예측을 평가합니다.
\[val_{x}(S)=val_{x}(\{x_{1},x_{3}\})=\int_{\mathbb{R}}\int_{\mathbb{R}}\hat{f}(x_{1},X_{2},x_{3},X_{4})d\mathbb{P}_{X_2X_4}-E_X(\hat{f}(X))\]이것은 선형 모델의 특성의 기여도와 유사하게 보입니다!
“값”이라는 단어를 여러 번 사용해도 혼동하지 마세요. 특성 값은 특성 및 관측치의 숫자 또는 범주형 값, Shapley value는 예측에 대한 특성의 기여도 그리고 값 함수는 선수(특성 값)의 연합에 대한 지불금 함수입니다.
Shapley value는 속성 효율, **대칭, **dummy*, **추가를 충족시키는 유일한 귀속방식이며, 함께 공정한 지불금의 정의로 간주될 수 있습니다.
효율성 특성의 기여도도은 x의 예측 차이와 평균을 더해야 합니다.
\[\sum\nolimits_{j=1}^p\phi_j=\hat{f}(x)-E_X(\hat{f}(X))\]대칭 두 특성값 j와 k의 기여도는 가능한 모든 협동에 균등하게 기여하는 경우 동일해야 합니다. 만약
\[val(S\cup\{x_j\})=val(S\cup\{x_k\})\]전적으로
\[S\subseteq\{x_{1},\ldots,x_{p}\}\setminus\{x_j,x_k\}\]그리고나서
\[\phi_j=\phi_{k}\]더미 특성 값의 연합에 관계없이 예측값을 변경하지 않는 특성 j는 shapley value이 0이어야 합니다. 만약
\[val(S\cup\{x_j\})=val(S)\]전적으로
\[S\subseteq\{x_{1},\ldots,x_{p}\}\]그리고나서
\[\phi_j=0\]추가 연합된 지불금이 있는 게임의 경우, 각 shapley value는 다음과 같습니다.
\[\phi_j+\phi_j^{+}\]당신이 임의의 숲을 훈련시켰습니다 고 가정해 보자. 이것은 예측이 많은 결정 나무들의 평균이라는 것을 의미합니다. Additivity 속성은 특성 값에 대해 각 트리의 shapley value를 개별적으로 계산하여 평균화하고 랜덤 포레스트의 특성 값에 대한 shapley value를 얻을 수 있음을 보장합니다.
이해
shapley value를 이해하는 직관적인 방법은 다음과 같습니다. 특성 값은 임의의 순서로 룸에 들어간다. 방안의 모든 특성 값은 게임에 참여합니다(= 예측에 기여합니다). 특성값의 shapley value는 특성값이 연합될 때 이미 룸에 있는 연합가 받는 예측의 평균 변화다.
Shapley Value 추정
특성 값의 가능한 모든 연합(세트)은 정확한 shapley value를 계산하기 위해 j번째 특성과 함께 그리고 없이 평가되어야 합니다. 몇 가지 이상의 특성에 대해서는, 더 많은 특성이 추가될수록 가능한 탄착의 수가 기하급수적으로 증가함에 따라, 이 문제에 대한 정확한 해결책이 문제가 됩니다. 스트럼벨지 외 연구진(2014)2은 몬테카를로 표본 추출에 대한 근사치를 제안합니다.
\[\hat{\phi}_{j}=\frac{1}{M}\sum_{m=1}^M\left(\hat{f}(x^{m}_{+j})-\hat{f}(x^{m}_{-j})-\right)\]여기서 \(\hat{f}(x^{m}_{+j})\)는 x에 대한 예측이지만, 특성 j의 각 값을 제외하고 임의의 수의 특성 값이 임의의 데이터 지점 z의 특성 값으로 대체됩니다. x-벡터 \(x^{m}_{-j}\)는 \(x^{m}_{+j}\)와 거의 동일하지만 \(x_j^{m}\) 값도 샘플링된 z에서 가져온다. 이러한 M의 새로운 관측치들은 각각 두 개의 관측치로부터 조립된 일종의 “프랑켄슈타인 몬스터”입니다.
단일 특성 값에 대한 대략적인 샤플리 추정:
- 출력: J번째 특성의 값에 대한 shapley value
- 필수: 반복 횟수 M, 관심 관측치 x, 특성 인덱스 j, 데이터 매트릭스 X 및 머신러닝 모델 f
- 모든 m = 1,…,M:
- 데이터 매트릭스 X에서 랜덤 관측치 z 그리기
- 특성값 중 무작위 순열 o 선택
- 관측치 x: \(x_o=(x_{(1)},\ldots,x_{(j)},\ldots,x_{(p)})\)
- 관측치 z: \(z_o=(z_{(1)},\ldots,z_{(j)},\ldots,z_{(p)})\)을(를) 주문하십시오.
- 두 개의 새 관측치 구성
- 특성 j: \(x_{+j}=(x_{(1)},\ldots,x_{(j-1)},x_{(j)},z_{(j)},z_{(j+1)},\ldots,z_{(p)}\)
- 특성 j: \(x_{-j}=(x_{(1)},\ldots,x_{(j-1)},z_{(j)},z_{(j)},z_{(j+1)},\ldots,z_{(p)}\)
- 한계 기여 계산: \(\phi_j^{m}=\hat{f}(x_{+j})-\hat{f}(x_{-j})\)
- shapley value를 평균으로 계산: \(\phi_j(x)=\frac{1}{M}\sum_{m=1}^M\phi_j^{m}\)
먼저 관심 관측치(instance) x, 특성 j 및 반복 횟수 M을 선택하십시오. 각 반복에 대해 데이터에서 임의 관측치 z를 선택하고 특성의 임의 순서가 생성됩니다. 두 개의 새로운 관측치는 관심 관측치 x와 표본 z의 값을 연합하여 생성됩니다. 첫 번째 관측치(instance) \(x_{+j}\)은(는) 관심 관측치(instance)이지만 특성 j의 이전 및 포함 값의 모든 값은 샘플 z의 특성 값으로 대체됩니다. 두 번째 관측치(instance) \(x_{-j}\)는 유사하지만, 이전의 모든 값을 가지고 있지만, 특성 j를 샘플 z에서 특성 j의 값으로 대체한 것을 제외합니다. 블랙박스와 예측의 차이가 계산됩니다.
\[\phi_j^{m}=\hat{f}(x^m_{+j})-\hat{f}(x^m_{-j})\]이러한 모든 차이는 평균화되며 다음과 같은 결과를 낳는다.
\[\phi_j(x)=\frac{1}{M}\sum_{m=1}^M\phi_j^{m}\]평균화는 X의 확률 분포에 의해 암묵적으로 표본의 가중치를 잰다.
모든 shapley value를 얻으려면 각 특성에 대해 절차를 반복해야 합니다.
장점
예측값과 평균 예측값의 차이는 shapley value의 효율성 특성인 관측치의 특성값 중 공정한 분포입니다. 이 특성은 shapley value를 LIME와 같은 다른 방법과 구별합니다. LIME은 예측이 특성들 사이에 공정하게 분포됩니다는 것을 보증하지 않는다. shapley value는 충분한 설명을 전달하는 유일한 방법일 수 있습니다. EU의 “설명권”과 같이 법이 설명가능성을 요구하는 상황에서 shapley value는 확고한 이론에 근거하고 효과를 공정하게 배분하기 때문에 법적으로 유일하게 준수하는 방법일 수 있습니다. 나는 변호사가 아니기 때문에 이것은 요구조건에 대한 나의 직감만을 반영합니다.
shapley value는 대조적 설명을 허용합니다. 예측을 전체 데이터 세트의 평균 예측과 비교하는 대신, 하위 집합 또는 단일 데이터 포인트에 비교할 수 있습니다. 이와 같은 대조도는 LIME과 같은 지역 모델에도 없는 것입니다.
shapley value는 고정 이론을 가진 유일한 설명 방법입니다. 효율성, 대칭성, 더미, 부가성 등 공리는 설명에 합리적인 근거를 제공합니다. LIME과 같은 방법은 로컬에서 머신러닝 모델의 선형 동작을 가정하지만, 이것이 왜 작동해야 하는지에 대한 이론은 없다.
특성적 가치들이 하는 게임**으로 예측을 설명하는 것은 **에 대한 마음을 설레게 합니다.
단점
shapley value는 많은 컴퓨팅 시간을 필요로 합니다**. 실제 문제의 99.9%에서는 대략적인 해결책만 실현 가능합니다. shapley value의 정확한 연산은 2^k^의 특성 값의 가능한 연합이 있고 특성의 “유용성”은 무작위 관측치를 그려 시뮬레이션해야 하기 때문에 계산적으로 비용이 많이 든다. 연탄의 지수수는 연탄을 샘플링하고 반복 M의 수를 제한하여 처리합니다. M을 줄이면 계산 시간은 줄어들지만 shapley value의 분산은 증가합니다. 반복 M의 숫자에 대한 손쉬운 규칙은 없다. M은 shapley value를 정확하게 추정할 수 있을 정도로 크지만, 합리적인 시간에 계산을 완료할 수 있을 만큼 작아야 합니다. 체르노프 경계에 근거하여 M을 선택하는 것은 가능해야 하지만, 나는 머신러닝 예측을 위한 shapley value에 대해 이것을 하는 것에 관한 어떤 논문도 본 적이 없다.
shapley value 를 잘못 해석할 수 있음 특성값의 shapley value는 모델 학습에서 특성을 제거한 후 예측값의 차이가 아닙니다. shapley value의 해석은 다음과 같습니다. 현재 특성 값 집합을 고려할 때 실제 예측과 평균 예측 간의 차이에 대한 특성 값의 기여는 추정 shapley value입니다.
shapley value는 희박한 설명(특성을 거의 포함하지 않는 설명)을 찾으면 잘못된 설명 방법입니다. Shapley value 메서드로 작성된 설명 항상 모든 특성을 사용합니다. 인간은 LIME에 의해 만들어진 것과 같은 선택적 설명을 선호합니다. 일반인들이 다루어야 하는 설명에는 LIME이 더 나은 선택일 수 있습니다. 또 다른 해결책은 SHAP)로 shapley value를 기반으로 하지만 특성도 거의 없는 설명을 제공할 수 있습니다.
shapley value는 특성당 단순한 값을 반환하지만, *LIME과 같은 예측 모델은 반환하지 않는다. 이는 다음과 같은 입력변동 예측변동에 대한 진술을 할 수 없음을 의미합니다. “연 300유로를 더 벌면 신용점수가 5점 정도 오를 겁니다.”
또 다른 단점은 새 데이터 관측치의 shapley value를 계산하려면 *** 데이터에 액세스해야 합니다는 것입니다. 관심 있는 관측치의 일부를 임의로 추출한 데이터의 관측치에서 얻은 값으로 대체하기 위해 데이터가 필요하기 때문에 예측 특성에 접근하는 것만으로는 충분하지 않다. 실제 데이터 관측치처럼 보이지만 학습 데이터에서 실제 관측치가 아닌 데이터 관측치를 생성할 수 있는 경우에만 이 문제를 피할 수 있습니다.
다른 많은 순무 기반 해석 방법과 마찬가지로 shapley value 방법은 특성이 상관되는 경우 *비현실적인 데이터 관측치를 포함시키는 문제를 겪는다. 연합에서 특성 값이 누락된 것을 시뮬레이션하기 위해 특성을 무시합니다. 이는 특성의 한계 분포에서 값을 표본 추출함으로써 달성됩니다. 특성이 독립적인 한 이것은 괜찮다. 특성이 종속된 경우, 이 관측치에 맞지 않는 특성 값을 샘플링할 수 있습니다. 하지만 우리는 그것들을 특성의 shapley value를 계산하는데 사용할 것입니다. 내가 아는 바로는, 그것이 샤플리에게 어떤 의미가 있는가에 대한 연구도, 그것을 어떻게 고칠 것일까요에 대한 제안도 없다. 한 가지 해결책은 상관된 특성을 함께 퍼머하고 그 특성에 대해 하나의 상호 shapley value를 얻는 것일 수 있습니다. 또는 특성의 의존성을 고려하여 표본 추출 절차를 조정해야 할 수 있습니다.
소프트웨어 및 대안책
shapley value는 ‘iml’ R 패키지에 구현됩니다.
shapley value에 대한 대체 추정 방법인 SHAP는 다음 장에 제시되어 있습니다.
또 다른 접근법은 breakDown(브레이크다운) R 패키지3에서 구현되는 breakDown(브레이크다운)이라고 합니다. 또한 BreakDown은 예측에 대한 각 특성의 기여도를 보여주지만, 차근차근 계산합니다. 게임 비유를 재사용해 봅시다. 빈 팀으로 시작하여 예측에 가장 큰 기여를 할 특성값을 추가하고 모든 특성값이 추가될 때까지 반복합니다. 각 특성값이 기여하는 정도는 이미 “팀”에 있는 각각의 특성 값에 따라 달라지는데, 이는 breakDown 방법의 큰 단점입니다. shapley value 방법보다 빠르며, 상호작용이 없는 모델의 경우 결과는 동일합니다.
-
Shapley, Lloyd S. “A value for n-person games.” Contributions to the Theory of Games 2.28 (1953): 307-317. ↩
-
Štrumbelj, Erik, and Igor Kononenko. “Explaining prediction models and individual predictions with feature contributions.” Knowledge and information systems 41.3 (2014): 647-665. ↩
-
Staniak, Mateusz, and Przemyslaw Biecek. “Explanations of model predictions with live and breakDown packages.” arXiv preprint arXiv:1804.01955 (2018). ↩