4.6 RuleFit
RuleFit
Friedman과 Popescu의 RuleFit 알고리즘(2008)1은 의사결정 규칙의 형태로 자동으로 탐지된 상호 작용 효과를 포함하는 희소 선형 모델을 학습합니다.
선형 회귀 모형은 특성 간 상호 작용을 고려하지 않습니다. 선형 모델처럼 단순하고 해석 가능한 모델을 가지면서도 특성 간의 상호 작용도 통합하는 것이 편리하지 않을까요? RuleFit이 이를 해결해줍니다. RuleFit은 원래 특성와 함께 희소 선형 모델을 학습하고 의사 결정 규칙인 여러 새 특성도 학습합니다. 이러한 새 특성은 원래 특성 간의 상호 작용을 고려합니다. RuleFit은 의사 결정 트리에서 이러한 특성을 자동으로 생성합니다. 트리를 통과하는 각 경로는 분할 결정을 규칙으로 결합하여 의사 결정 규칙으로 변환할 수 있습니다. 노드 예측은 제외하고 분할만 의사 결정 규칙에 사용됩니다.
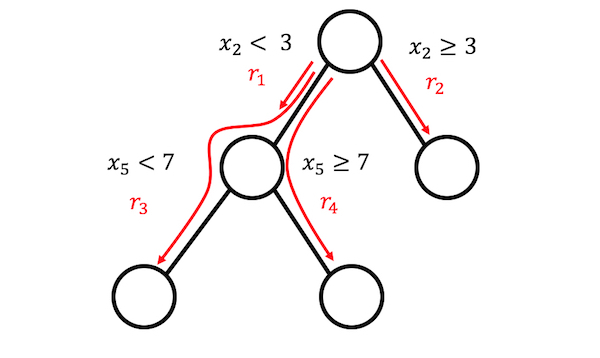
그림 4.21: 4개 규칙은 3개의 터미널 노드가 있는 트리에서 생성할 수 있습니다.
그 의사결정 트리들은 어디서 왔을까요? 트리는 관심의 결과를 예측하도록 훈련됩니다. 이렇게 하면 예측하는데 의미가 있는 분할을 만듭니다. RuleFit은 트리를 많이 생성하는 모든 알고리즘을 사용할 수 있습니다(예: 랜덤 포레스트). 각 트리는 희소 선형 회귀 모형(Lasso)에서 추가 특성으로 사용되는 의사 결정 규칙으로 분해됩니다.
RuleFit 논문은 보스턴 주택 데이터를 사용하여 다음 사항을 설명합니다.
목표는 보스턴 지역의 중간 주택 값을 예측하는 것입니다.
RuleFit에서 생성된 규칙 중 하나는 다음과 같습니다.
만약 number of rooms > 6.64 이고 concentration of nitric oxide <0.67 이면 1 아니면 0이다.
또한 RuleFit에는 예측에 중요한 선형 항 및 규칙을 식별하는 데 도움이 되는 특성 중요도 측정이 함께 제공됩니다. 특성 중요도는 회귀 모형의 가중치로 계산됩니다. 중요도 측정은 원래 특성(“원형” 형식 및 많은 의사결정 규칙에서 사용됨)에 대해 계산할 수 있습니다.
RuleFit에는 특성를 변경하여 예측의 평균 변화를 보여 주는 부분 의존도 그림도 있습니다. 부분 의존도는 어떤 모델에서도 사용할 수 있는 model-agnostic 방식이며, 부분 의존도 그림에 관한 장에서 설명합니다.
해석과 예시
RuleFit은 결국 선형 모델을 추정하므로 해석은 “일반적인” 선형 모델과 동일합니다. 유일한 차이점은 모형에 의사결정 규칙에서 파생된 새로운 특성이 있다는 것입니다. 의사 결정 규칙은 다음과 같은 2진수 특성입니다. 값이 1이면 규칙의 모든 조건이 충족되고 그렇지 않으면 값이 0입니다. RuleFit의 선형 항에 대한 해석은 선형 회귀 모형에서와 동일합니다. 특성이 한 단위 증가하면 예측 결과가 해당 특성 가중치에 따라 변경됩니다.
이 예에서는 RuleFit를 사용하여 특정일의 자전거 대여 수를 예측합니다. 다음 표는 RuleFit에 의해 생성된 다섯 가지 규칙과 해당 lasso 가중치 및 중요도를 보여 줍니다. 계산은 장의 뒷부분에 설명되어 있습니다.
| Description | Weight | Importance |
|---|---|---|
| days_since_2011 > 111 & weathersit in (“GOOD”, “MISTY”) | 793 | 303 |
| 37.25 <= hum <= 90 | -20 | 272 |
| temp > 13 & days_since_2011 > 554 | 676 | 239 |
| 4 <= windspeed <= 24 | -41 | 202 |
| days_since_2011 > 428 & temp > 5 | 366 | 179 |
가장 중요한 규칙은 days_since_2011 > 111 & weathersit in (“GOOD”,”MISTY”)였으며, 가중치는 793입니다. 해석은 다음과 같습니다. days_since_2011 > 111 & weathersit in (“GOOD”,”MISTY”) 인 경우, 다른 모든 특성 값이 고정되어 있을 때 예상 자전거 수는 793개 증가합니다. 총 278개의 규칙이 기존에 있던 8개의 특성에서 생성되었습니다. 꽤 많이요! 하지만 라소 덕분에 278개 중 겨우 58개만이 0이 아닌 가중치를 가지고 있습니다.
글로벌 특성 가져오기 특성을 계산하면 온도 및 시간 추세가 가장 중요한 특성임을 알 수 있습니다.

그림 4.21: 자전거 수를 예측하는 RuleFit 모델에 대한 특성 중요도 측정입니다. 예측의 가장 중요한 특징은 온도 및 시간 추세입니다.
특성 중요도 측정에는 기존 특성 항과 특성이 나타내는 모든 의사 결정 규칙이 포함됩니다.
해석 방법
해석은 선형 모형과 유사합니다. 다른 모든 특성이 변경되지 않은 경우 특성 \(x_j\)이(가) 한 단위로 변경될 경우 예측 결과가 \(\beta_j\)만큼 변경됩니다. 의사결정 규칙의 가중치 해석은 조금 다릅니다. 의사결정 규칙 \(r_k\)의 모든 조건이 적용되는 경우 예측 결과는 \(\alpha_k\)(선형 모델에서 규칙 \(r_k\)의 학습된 가중치)만큼 변경됩니다.
분류의 경우(선형 회귀 분석 대신 로지스틱 회귀 분석을 사용합니다): 의사결정 규칙 \(r_k\)의 모든 조건이 적용되는 경우 사건 대 사건 없음의 확률이 \(\alpha_k\)의 비율로 변화됩니다.
이론
RuleFit 알고리즘의 세부 사항에 대해 자세히 살펴보겠습니다. RuleFit은 두 가지 구성 요소로 구성됩니다. 첫 번째 구성 요소는 의사 결정 트리에서 “규칙”을 생성하고 두 번째 구성 요소는 기존 특성과 새 규칙을 입력(“RuleFit”이라는 이름)으로 선형 모델을 학습시킵니다.
1 단계: 규칙 생성
규칙은 어떻게 생겼나요? 알고리즘에서 생성된 규칙은 간단한 형식을 가집니다. 예를 들어 다음과 같습니다. 만약 “x2 < 3”과 “x5 < 7”이 1 ELSE 0이면. 규칙은 의사결정 트리를 분해하여 구성됩니다. 트리의 노드에 대한 모든 경로를 의사 결정 규칙으로 변환할 수 있습니다. 규칙에 사용되는 트리는 목표 결과를 예측하는 데 적합합니다. 따라서 분할 및 결과 규칙은 관심 있는 결과를 예측하도록 최적화됩니다. 특정 노드로 이어지는 이진 결정을 “AND”로 연결하기만 하면 됩니다. 다양하고 의미 있는 규칙을 많이 만드는 것이 좋습니다. Gradient Boosting은 원래 특징인 X로 y를 회귀하거나 분류하여 의사결정 트리의 앙상블을 학습하는데 사용됩니다. 각 결과 트리는 여러 규칙으로 변환됩니다. RuleFit용 트리를 생성하는 데 트리 앙상블 알고리즘을 사용할 수 있습니다. 트리 앙상블은 다음과 같은 공식을 사용하여 설명할 수 있습니다.
\[f(x)=a_0+\sum_{m=1}^M{}a_m{}f_m(X)\]M은 트리의 수이며 \(f_m(x)\)는 m번째 트리의 예측 함수입니다. \(\alpha\)가 가중치입니다. Bagged 앙상블, 랜덤 포리스트, AdaBoost 및 MART는 트리 앙상블을 생성하며, RuleFit에 사용할 수 있습니다.
앙상블의 모든 트리에서 규칙을 만듭니다. 각 규칙 \(r_m\)의 형식은 다음과 같습니다.
\[r_m(x)=\prod_{j\in\text{T}_m}I(x_j\in{}s_{jm})\]여기서 \(T_{m}\)은(는) m-three에서 사용되는 특성 집합으로, \(x_j\) 특성이 j-th 특성(트리 분할에서 지정한 대로)에 대한 값의 지정된 하위 집합에 있을 때 1인 항등 함수입니다. 숫자 특성의 경우 \(s_{jm}\)은 특성 값 범위의 간격입니다. 간격은 다음 두 경우 중 하나로 나타냅니다.
\[x_{s_{jm},\text{lower}}<x_j\] \[x_j<x_{s_{jm},upper}\]이 특성이 더 많이 분할되면 간격이 더 복잡해질 수 있습니다. 범주형 특성의 경우 부분 집합에는 특성의 특정 범주가 포함됩니다.
자전거 대여 데이터의 예는 다음과 같습니다.
\[r_{17}(x)=I(x_{\text{temp}}<15)\cdot{}I(x_{\text{weather}}\in\{\text{good},\text{cloudy}\})\cdot{}I(10\leq{}x_{\text{windspeed}}<20)\]이 규칙은 세 가지 조건이 모두 충족되면 1을 반환하고, 그렇지 않으면 0을 반환합니다. RuleFit은 리프 노드뿐만 아니라 트리에서 가능한 모든 규칙을 추출합니다. 그래서 만들어진 또 다른 규칙은 다음과 같습니다.
\[r_{18}(x)=I(x_{\text{temp}}<15)\cdot{}I(x_{\text{weather}}\in\{\text{good},\text{cloudy}\}\]모두 합쳐서 \(t_m\) 중간 노드가 있는 M개의 트리 앙상블에서 생성된 규칙 수는 다음과 같습니다.
\[K=\sum_{m=1}^M2(t_m-1)\]RuleFit 저자들이 도입한 수법은 길이가 다른 다양한 규칙이 생성되도록 트리의 깊이를 다양하게 배우는 것입니다. 각 노드에서 예측된 값을 삭제하고 노드로 이어지는 조건만 유지한 다음 노드에서 규칙을 생성합니다. 결정 규칙의 가중치는 RuleFit의 2단계에서 수행됩니다.
1단계를 확인할 수 있는 또 다른 방법입니다. RuleFit는 원래 특성에서 새 특성 집합을 생성합니다. 이러한 특성는 2진수이며 원래 특성의 매우 복잡한 상호 작용을 나타낼 수 있습니다. 규칙은 예측 작업을 최대화하기 위해 선택됩니다. 규칙은 공변량 행렬 X에서 자동으로 생성됩니다. 규칙을 원래 특성에 따라 새 특성으로 볼 수 있습니다.
2 단계: 희소 선형 모델
1단계에서는 규칙을 아주 많이 생성합니다. 첫 번째 단계는 특성 변환으로만 볼 수 있으므로 모델을 학습하는 과정은 아직 완료되지 않았습니다. 또한 규칙 수를 줄여야합니다. 규칙 외에도 원래 데이터 세트의 “원래” 특성이 모두 희소 선형 모델에서도 사용됩니다. 모든 규칙과 모든 기존 특성은 선형 모형의 특성이 되고 가중치 추정치를 얻습니다. 트리가 y와 x 사이의 단순한 선형 관계를 나타내지 못하기 때문에 원래 기존 특성이 추가됩니다. 희소 선형 모형을 학습하기 전에 원래 특성이 이상치에 대해 보다 견고하도록 동등화합니다.
\[l_j^*(x_j)=min(\delta_j^+,max(\delta_j^-,x_j))\]여기서 \(\delta_j^-\) 및 \(\delta_j^+\)는 특성 \(x_j\)의 데이터 분포에 대한 \(\delta\) 분위수입니다. \(\delta\) 에 대해 0.05를 선택하면 5% 최저값 또는 5% 최고값인 특성 \(x_j\) 값이 각각 5% 또는 95%로 정량형으로 설정됩니다. 일반적으로 \(\delta\) = 0.025를 선택합니다. 또한 선형 항은 일반적인 의사결정 규칙과 동일한 사전 중요도를 가지도록 정규화되어야 합니다.
\[l_j(x_j)=0.4\cdot{}l^*_j(x_j)/std(l^*_j(x_j))\]\(0.4\)는 균일 배포가 \(s_k\sim{}U(0.1)\)인 규칙의 평균 표준 편차입니다. 두 가지 유형의 특성를 결합하여 새로운 특성 매트릭스를 생성하고 다음과 같은 구조로 희소 선형 모델을 교육합니다.
\[\hat{f}(x)=\hat{\beta}_0+\sum_{k=1}^K\hat{\alpha}_k{}r_k(x)+\sum_{j=1}^p\hat{\beta}_j{}l_j(x_j)\]여기서 \(\hat{\alpha}\)는 규칙 특성의 예상 가중치 벡터이고 \(\hat{\beta}\) 원래 특성의 가중치 벡터입니다. RuleFit은 Lasso를 사용하기 때문에 손실 함수는 일부 가중치가 영점 추정치를 얻도록 하는 추가 제약조건을 얻습니다.
\[(\{\hat{\alpha}\}_1^K,\{\hat{\beta}\}_0^p)=argmin_{\{\hat{\alpha}\}_1^K,\{\hat{\beta}\}_0^p}\sum_{i=1}^n{}L(y^{(i)},f(x^{(i)}))+\lambda\cdot\left(\sum_{k=1}^K|\alpha_k|+\sum_{j=1}^p|b_j|\right)\]그 결과 모든 원래 특성과 규칙에 대해 선형 효과가 있는 선형 모형이 됩니다. 해석은 선형 모형과 동일합니다. 유일한 차이점은 일부 특성이 이제 이진 규칙이라는 것입니다.
3 단계 (선택): 특성 중요도
원래 특성의 선형 항에 대해 특성 중요도는 표준화된 예측 변수를 사용하여 측정됩니다.
\[I_j=|\hat{\beta}_j|\cdot{}std(l_j(x_j))\]여기서 \(\beta_j\)는 Lasso 모델의 가중치이고 \(std(l_j(x_j)\)는 데이터에 대한 선형 항의 표준 편차입니다.
의사결정 규칙 용어의 중요도는 다음 공식을 사용하여 계산됩니다.
\[I_k=|\hat{\alpha}_k|\cdot\sqrt{s_k(1-s_k)}\]여기서 $\hat{\alpha}_k$는 의사결정 규칙의 관련 희소 가중치이고 \(s_k\)는 데이터에서 해당 특성의 지원입니다(여기서 \(r_k(x)=0\)).
\[s_k=\frac{1}{n}\sum_{i=1}^n{}r_k(x^{(i)})\]특성은 선형 항으로 발생하며, 많은 의사결정 규칙에서도 발생할 수 있습니다. 특성의 총 중요도를 어떻게 측정할까요? 각 개별 예측에 대해 특성의 중요도 $J_j(x)$를 측정할 수 있습니다.
\[J_j(x)=I_j(x)+\sum_{x_j\in{}r_k}I_k(x)/m_k\]여기서 $I_j$는 선형 용어의 중요성이고 $I_k$는 $x_j$가 나타나는 결정 규칙의 중요성이며 $m_k$는 규칙 $r_k$을(를) 구성하는 특성의 수입니다. 모든 관측치에서 특성 중요도를 추가하면 글로벌 특성이 중요해집니다.
\[J_j(X)=\sum_{i=1}^n{}J_j(x^{(i)})\]관측치의 하위 집합을 선택하고 이 그룹에 대한 특성 중요도를 계산할 수 있습니다.
장점
RuleFit은 선형 모형에 특성 상호 작용을 자동으로 추가합니다. 따라서 상호 작용 항을 수동으로 추가해야 하는 선형 모델의 문제를 해결하고 비선형 관계 모델링 문제를 해결하는 데 도움이 됩니다.
RuleFit은 분류 및 회귀 작업을 모두 처리할 수 있습니다.
생성된 규칙은 2진수 결정 규칙이기 때문에 쉽게 해석할 수 있습니다. 규칙이 관측치에 적용되거나 적용되지 않습니다. 규칙 내의 조건 수가 너무 크지 않은 경우에만 양호한 해석성이 보장됩니다. 개인적으로 1에서 3까지 조건이 있는 규칙이 적당해보입니다. 이는 트리 앙상블에 있는 트리의 최대 깊이가 3이라는 것을 의미합니다.
모델에 많은 규칙이 있더라도 모든 관측치에 적용되지 않습니다. 개별 관측치의 경우 소수의 규칙만 적용됩니다(= 0이 아닌 가중치를 가짐). 이렇게 하면 로컬 해석성이 향상됩니다.
RuleFit은 여러 가지 유용한 진단 도구를 제안합니다. 이러한 도구는 모델에 제한이 없으므로 특성 중요도, 부분 의존도 그림 및 특성 상호 작용의 model-agnostic에서 찾을 수 있습니다.
단점
때때로 RuleFit은 Lasso 모델에서 0이 아닌 무게를 갖는 많은 규칙을 만듭니다. 해석성은 모델의 특성 수가 증가함에 따라 저하됩니다. 유망한 해결책은 특성 효과를 단조로이 하도록 강제하는 것인데, 이는 특성의 증가가 예측의 증가를 이끌어야 한다는 것을 의미합니다.
일화적인 단점으로 논문에서는 RuleFit가 랜덤 포레스트의 예측 성능과 비슷하다고 주장합니다. 하지만 제가 개인적으로 시도했던 몇 안 되는 경우에는 실망스러웠습니다. 문제를 해결하고 어떻게 작동하는지 확인하기만 하면 됩니다.
RuleFit 절차의 최종 결과물은 추가적인 화려한 특징(결정 규칙)을 가진 선형 모델입니다. 그러나 그것은 선형 모델이기 때문에, 가중치 해석은 여전히 현실적이지 않습니다. 일반적인 선형 회귀 모델과 동일한 “가정”이 제공됩니다. “…모든 특성이 고정되어 있습니다.” 중복되는 규칙이 있으면 좀 더 까다로워집니다. 예를 들어 자전거 예측에 대한 하나의 결정 규칙(특성)은 “temp > 10”일 수 있고, 다른 규칙은 “temp > 15 & weather=’GOOD’“일 수 있습니다. 만약 날씨가 좋고 온도가 15도 이상이라면, 온도는 자동적으로 10도보다 더 커집니다. 두 번째 규칙이 적용되는 경우 첫 번째 규칙도 적용됩니다. 두 번째 규칙에 대한 추정 가중치의 해석은 다음과 같습니다. “다른 모든 특성이 고정되어 있다고 가정하면, 날씨가 좋고 온도가 15도 이상일 때 예상 자전거 수는 \(\beta_2\) 증가합니다.” 그러나 이제 ‘다른 모든 특성 고정’이 문제가 된다는 것은 분명해집니다. 규칙 2가 적용되면 규칙 1도 적용되고 해석도 비논리적이기 때문입니다.
소프트웨어 및 대체방법
RuleFit 알고리즘은 Fokkema 및 Christopersen(2017)2에 의해 R에 구현되어 있고, Python 버전은 Github에서 확인할 수 있습니다.
매우 유사한 프레임워크는 Skope-rules입니다. 이 또한 앙상블에서 규칙을 추출하는 Python 모듈입니다. 최종 규칙을 학습하는 방식에 따라 다릅니다. 첫째, skope-rules은 재현성 및 정밀도 임계값을 기준으로 성능이 낮은 규칙을 제거합니다. 그런 다음, 규칙의 논리 항(변수 + 더 큰/작은 연산자)과 성능(F1 점수)의 다양성에 따라 선택을 수행함으로써 중복 및 유사한 규칙이 제거됩니다. 이 마지막 단계는 Lasso를 사용하는 것에 의존하지 않고, 규칙을 형성하는 논리 항인 F1 점수만을 고려합니다.