
Survey report of Federated Learning
얼마 전 대학원 면접을 통해 새롭게 알게 된 방법이 있었으니 바로 Federated Learning(FL) 이다. 그동안 궁금했던 건데 왜 진작 못 들어 봤을까 하는 아쉬움이 크다.
병원에서 일하면서 느꼈던 점 중 하나는 연구 결과에서도 그렇고 병원마다 가지고 있는 데이터가 같은 질병에 대해서도 인구통계학적으로나 여러 방면에서 꽤 다르다는 것을 알게 되었다1. 그렇게 해서 시작한 과제가 CDM 사업으로 알았고 미국에서는 잘된다고 들어서 한국에도 아주대 병원을 중심으로 잘되어 있는 줄 알았다. 그러나 하나둘씩 잘되고 있다는 소식은 거의 없었고 내 기억 속에서는 그냥저냥 잊혀 가고 있었다.
그러다가 최근에 알게 된 FL을 인제야 찾아보게 되었다. 최근에 정말 여러 가지로 의료 쪽에서 많은 연구가 있는 것 같다. Neural ODE도 그렇고 참 좋은 방법들인 거 같은데 왜 그동안 사람들의 눈에 잘 안 띄었을까 싶은 생각이 든다. 내가 안 찾아본 거다.
어쨌든 이렇게 알게 된거 배경과 방법 그리고 연구 방향은 어떻게 있는지 찾아보았다.
Introduction
정의
연합 학습(federated learning, FL) 이란 이름에서 알 수 있듯이 다양한 사용자 또는 기관으로부터 데이터를 받아서 학습하는 방법을 말한다. 하지만 여기서 주고받는 데이터는 원본 데이터(raw data)가 아닌 중간 데이터를 말한다. 중간 데이터란 원본 데이터를 통해 얻은 결과물이다. 예를 들어 분산된 모델에 각 로컬의 데이터를 입력값으로 넣었을 때 결과 값에 대한 기존 가중치를 개선할 수 있는 기울기(gradients)도 중간 데이터라고 할 수 있다. 즉, 이러한 기울기 또는 가중치를 주고받으며 로컬에 있는 원본 데이터는 보호된 채 보다 일반화된(robust) 모델을 학습할 수 있는 방법은 연합 학습이라고 한다. 구글은 2017년 Google AI Blog를 통해 그림 12과 같이 이러한 연합 학습 방법을 서비스에 사용하겠다고 발표했다.

그림 1. A에서 사용자의 데이터를 기반으로 모델이 학습된다. B에서는 여러 사용자에 의해 학습된 정보를 집계(aggregation)한다. C에서는 이러한 업데이트된 정보들을 반영하여 다시 사용자의 모바일에 업데이트된 모델을 반영한다. 이후는 이 과정을 반복한다.
탄생 배경
Federated Learning 이라는 단어는 2016년에 Google AI에서 나온 Communication-Efficient Learning of Deep Networks from Decentralized Data 에서 처음 언급되었다. 그림 23과 같이 GSMA에 따르면 2020년에 이르러 모바일 기기를 사용하는 사람의 수는 50억 명에 달한다. 전 세계 인구의 3분의 1이 가입자라니.. 놀라울 따름이다. 점점 더 많은 사람이 보유하고 있는 기기들을 통해 수많은 데이터를 만들어내고 이러한 데이터로 모델을 학습하여 사용자들의 편의를 향상할 수 있다. 그러나 이러한 사용자 데이터에는 민감한 정보들이 많이 포함되어있고 서버에 저장하기에는 큰 비용이 들어가기 때문에 서버로 데이터를 업로드하지 않고 개인의 프라이버시를 유지하면서 모델을 학습하기 위해 이러한 방법을 제안하였다4.

그림 2. GSMA Mobile Economy 2020 reports
분산 학습과의 차이
여러 로컬에서 나누어 모델을 학습한다는 측면에서 분산 학습(distributed learning) 과 어떤 차이가 있는지도 궁금할 수 있다. 분산 학습과 연합 학습은 차이가 무엇인지 알아보자.
연합 학습과의 차이5는 기본적으로 그 가정이 다르다. 분산 학습의 경우 하나의 모델을 병렬적으로 학습하기 위한 것이고, 각 데이터가 독립적이고 동일한 분포(i.i.d.)를 가진다고 가정한다. 그러나 연합 학습의 경우 서로 이질적인(heterogeneous) 데이터를 학습하기 때문에 분산 학습과 같은 가정을 따르지 않아도 된다. 이러한 가정을 따르지 않기 때문에 발생하는 문제도 있는데, 이는 각 로컬에서 학습에 참여하는 사용자와의 소통(communication)이 원활하지 않고 학습 환경이 다를 수 있는 문제가 있다. 연합 학습에서는 분산 학습과 달리 크게 아래와 같이 네 가지 속성에 대해 최적화하기 위한 방향성을 제시한다.
- Non-IID : 각 사용자가 만들어낸 데이터의 분포가 서로 다를 수 있다.
- Unbalanced : 특정 사용자가 다른 사용자들에 비해 더 많은 비중을 차지할 수 있다.
- Massively distributed : 사용자별 데이터보다 사용자가 더 많을 수 있다.
- Limited communication : 모바일 기기가 오프라인이거나 느리거나 과도하게 연결이 많을 수 있다.
연합 학습을 적용하기 위해서는 실제로 발생하는 여러 문제를 해결할 필요가 있다. 예를 들어서 사용자는 데이터를 지우기도 하고 추가하기도 하며 사용자와의 연결이 서로 다르거나 업데이트에 동의하지 않을 수도 있다.
Methodology
모델 업데이트 방법
연합 학습에 대한 정의와 탄생 배경에 대해서 알아보았다. 그렇다면 이번에는 학습 방법은 어떻게 되는지 찾아보았다. 처음 나왔던 federated learning 논문에서는 크게 FedSGD 와 FedAVG 두 가지 학습 방법을 소개한다.
FedSGD는 기존 로컬에서 모델을 학습하는 SGD 방법을 연합 학습에 적용한 것이다. FedSGD에서 필요한 하이퍼파라미터 C가 있다. 여기서 C는 사용자를 기준으로 하는 batch size를 말한다. 예를 들어 C가 1인 경우 모든 사용자의 데이터를 사용하겠다는 의미이다. 각 로컬에서 업데이트된 가중치는 식 1과 같이 평균값을 계산하여 업데이트 된다. 식에서 \(g\)는 gradient, \(w\)는 weight, \(\eta\)는 learning rate, \(n\)은 data의 수, 그리고 \(K\)는 사용자의 수를 말한다. FedSGD는 federated learning의 성능을 비교하기 위한 베이스라인으로 사용된다.
\[w_{t+1} \leftarrow w_{t} - \eta \sum_{k=1}^{K} \frac{n_k}{n}g_{k} \ \ \ \ (1)\]FedAVG는 앞서 설명했던 FedSGD가 가지는 한계점들을 극복하기 위해 제안한 방법이다. 사용자와 서버가 소통할 수 있는 속도(bandwidth)에는 한계가 있기 때문에 빈도를 줄이기 위해 사용된다. 또한, 사용자의 환경에서 단순히 기울기를 구하는 과정보다 복잡한 연산을 통해 매 업데이트마다 각 사용자가 독립적이고 더 효율적으로 연합 학습을 구성하기 위한 방법이다. FedAVG에는 세 가지 하이퍼파라미터 \(C\), \(E\), 그리고 \(B\)가 있다. \(C\)는 앞서 설명한 값이고, \(E\)는 epoch(전체 데이터를 몇 번 반복할 것인지), 그리고 \(B\)는 batch size(학습 시 들어가는 데이터 크기)를 말한다.
사용자 수에 따른 연합 방법
처음 연합 학습이 소개되었을 때는 수많은 사용자의 디바이스와 어플리케이션을 통해 학습된 것으로 소개되었다. 그러나 연합 학습에 참여하는 사용자의 수에 따라 접근하는 연합 학습 방법은 수많은 사용자를 대상으로 하는 “cross-device“와 소수의 신뢰 있는 사용자를 대상으로 하는 “cross-silo” 두 가지로 구분될 수 있다6.
표 1은 두 방법 간의 차이를 잘 나타내고 있다. Cross-device는 100명 이상의 사용자가 사용하는 서비스 같은 곳에 적용하는 방법이다. 하지만 사용자가 많은 만큼 소통하는 데 들어가는 비용과 신뢰성에 문제가 생길 수 있다. 이와 반대로 cross-silo는 의료나 금융과 같이 소수의 기관을 대상으로 사용하는 연합 학습 방법이다. 수가 적은 만큼 소통 비용과 학습이 잘못될 가능성이 낮다. 하지만 민감한 데이터를 다루기 때문에 보다 프라이버시 보호와 보안에 주의를 기울여야 한다.

표 1. 분산 학습과 연합 학습 환경의 차이 비교. 연합 학습에서는 cross-silo와 cross-device의 특징도 함께 비교
여기서 잠깐, 프라이버시 보호와 보안이 어떤 차이인지 알아보자. 프라이버시 보호란 어떠한 데이터 공개 및 데이터 분석 결과로부터 특정 개인에 대한 정보가 누출되지 않음을 보장하는 것을 말한다. 한편, 보안은 정보 교환 시 정보의 기밀설을 보장하는 것을 말한다7.
표 에서 보면 data partition axis에 따른 차이가 있음을 알 수 있다. 데이터를 나누는 축에 따라 그림 3과 같이 Horizontal FL과 Vertical FL 두 가지 방법이 있다. Horizontal FL은 공통된 특성을 공유하는 여러 사용자 간의 데이터를 학습하는 방법이다. 예를 들어 서로 다른 지역 은행에 서로 다른 고객이 있는데 그들의 사업이 비슷한 경우를 말한다. 반면 Vertical FL의 경우 공통된 유저의 특성이 분산되어 있는 경우를 말한다. 예를 들어 하나의 도시에 은행과 이커머스 회사가 있을 때 두 회사의 사용자는 해당 도시의 사는 사람들이라는 공통점이 있지만 서로 다른 특성이 있다는 차이점이 있다. vertial FL은 이러한 점을 활용하여 유저들의 서로 다른 특성을 연합하여 상품 구매와 같은 다른 목표 값에 대한 예측에 사용할 수 있다8.

그림 3. 연합 학습의 종류
평가 방법
Federated Analytics
연합 학습을 찾아보면서 들었던 생각은 각 로컬에 있는 데이터의 퀄리티를 어떻게 보장할까 였다. 그러나 걱정도 잠시, 찾아보니 올해 5월 27일에 로컬 데이터의 퀄리티를 평가하는 방법인 federated analytics를 Google이 AI blog를 통해 공개했다9. 역시 결과에 대한 평가 방법을 내놓지 않을 구글이 아니다. (주제와는 별개로 이전에 computer vision의 XAI에 대해 공부할 때 슬슬 attribution method만 나올 게 아니라 정량적으로 어떻게 평가할지에 대해 나와야 하지 않으냐고 싶었는데 바로 ROAR and KAR과 같은 연구를 공개해주는 구글이 정말 빠르게 흐름을 잘 이어가고 선두하고 있다고 생각한다.. 그리고 정말 아이디어는 간단한데 왜 이런 생각을 안 해봤을까 싶은 연구도 꽤 많다는 점에서 참 신기하다)
federated analytics는 단순하다. 그림 4과 같이 federated learning 구조를 재활용하는 것이다. 단, 학습은 하지 않는다. 모델의 오차와 성능을 나타낼 수 있는 지표를 가지고 federated learning을 통해 학습했던 모델이 이전 데이터를 다시 활용하여 계산했을 때 발생하는 오차와 지표로 각 로컬의 데이터가 얼마나 모델의 성능을 향상했는지 평가할 수 있다. 이러한 평가 방법을 통해 각 로컬의 기여 정도를 파악할 수 있고 적절한 하이퍼파라미터를 정하는 데 도움이 될 수 있다10.

그림 4. (A) 글로벌 모델을 각 디바이스에 배포한다. (B) 글로벌 모델을 통해 사용자의 데이터를 학습한다. (C) 사용자의 데이터에 학습된 모델과 글로벌 모델의 오차와 평가 지표를 개산한다. (D) 모든 사용자들의 정보를 서버로 전송 한다. (E) 계산된 결과에 대해 히스토그램으로 나타낸다.
Data Shapley
2019년에는 Stanford 대학에서 Data Shapley에 대한 논문이 나왔다. 기존 Shapley Value에 대한 연구가 특성별로 계산되었다면 data shapley는 각 observation에 대한 중요도를 계산하는 방법이다11.
AI프렌즈 유튜브의 FL 강의 영상7에서 나왔던 질문 중 각 로컬마다 모델 성능 향상에 기여한 점을 기준으로 보상해주는 시스템을 제공하는 정책(?)을 마련할 수 있지 않을까 라는 대답으로 위의 두 방법이 되지 않을까 싶다. 또는 모델의 성능을 크게 떨어트리는 디바이스나 기기를 위주로 learning rate를 조절하는 방향도 있지 않을까 싶다.
Related Works
구글 Gboard
2016 연합 학습이라는 말이 나온 뒤로 여러 연구 논문들과 활용 사례들이 나오고 있다. 우선 가장 첫 번째로 연합 학습이 적용된 서비스는 구글의 Gboard이다. 그림 52과 같이 각 사용자가 입력할 단어를 예측해주는 기능이다.
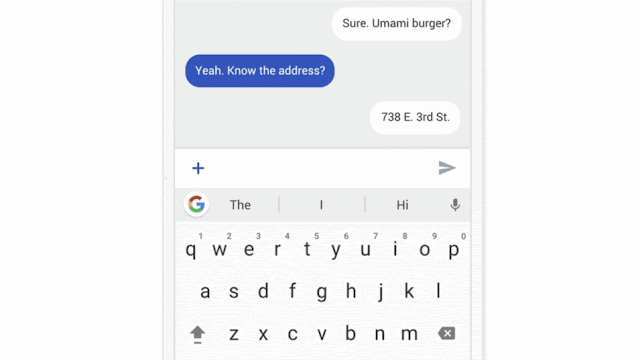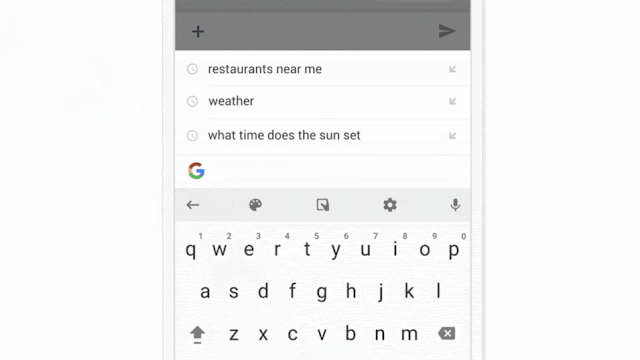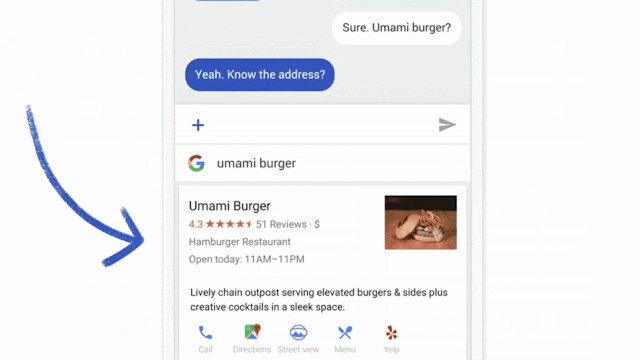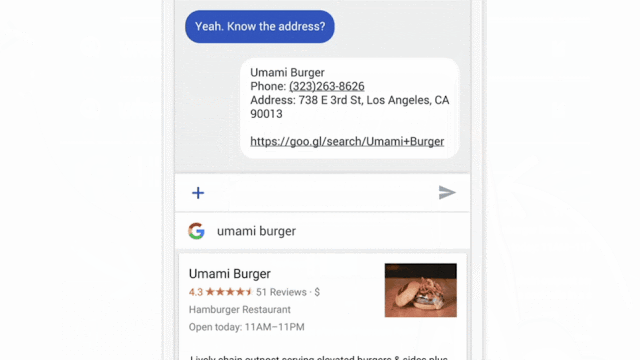
그림 5. 구글 Gboard 서비스 예시
첫 의료 영상 분야에서의 FL
2018년 MICCAI에서는 처음으로 의료 영상 데이터에 연합 학습을 적용한 연구 논문이 나왔다. Penn의 CBICA 랩과 인텔이 함께한 연구로 데이터를 공유하지 않는 세 가지 학습 방법을 비교하였다. 학습 방법은 각각 Institutional Incremental Learning (IIL), Cyclic Institutional Learning (CIIL), 그리고 FL 이다. IIL은 각 기관 마다 하나씩 돌아가며 모델을 학습하는 방법이다. 이 방법은 오래된 기관의 데이터를 학습한 가중치가 점점 잊히게 된다는 단점이 있다. CIIL은 IIL을 보완한 방법으로 이전의 학습 가중치가 잊히지 않도록 적절한 epoch를 정하여 IIL을 반복하는 방법이다. 그러나 이 역시 FL에 비해 효율적이지 못하다. 그 결과는 그림 6을 통해 data를 공유하는 방법까지 총 네 가지 방법의 성능 차이를 비교하였고 결과적으로 FL이 Data-Sharing에 가장 가까운 성능을 냈음을 확인할 수 있다12.

그림 6. Data-Sharing, FL, CIIL, 그리고 IIL의 brain tumar segmentation 성능 비교. 성능 지표는 Dice Coefficient이다.
FL 플랫폼 NVIDIA Clara
2019년에는 MICCAI에서 NVIDIA와 King’s College London의 뇌공학 연구자들이 함께 연구한 brain tumor segmentation에 대한 논문이 발표되었다. 환자들의 데이터를 전송하지 않고 가중치만 공유하여 연합 학습을 하였다. 공유하는 과정에서 업데이트된 가중치나 모델의 가중치 부터도 정보가 유추될 위험이 있기 때문에 selective parameter sharing과 sparse vector technique (SVT)를 사용하여 보완하였다1314.
두 방법에 대해 간단히 설명하자면 selective parameter sharing은 각 로컬에서 모든 가중치를 공유하는 것이 아닌 선택적으로 일정한 기준(threshold)를 통해 가중치 일부분만 공유하는 방법이다. SVT는 differential privacy를 갖추기 위해 노이즈를 추가하여 노이즈가 추가된 가중치를 공유하는 것이다. 적용 순서로는 seletive parameter sharing을 먼저 수행한 후 SVT를 적용하였다. Differential privacy가 무엇인지는 이후 Limitations에서 설명하기로 한다.
NVIDIA에서는 이 연구를 통해 연합 학습을 사용하는 플랫폼인 NVIDIA Clara를 소개했다.
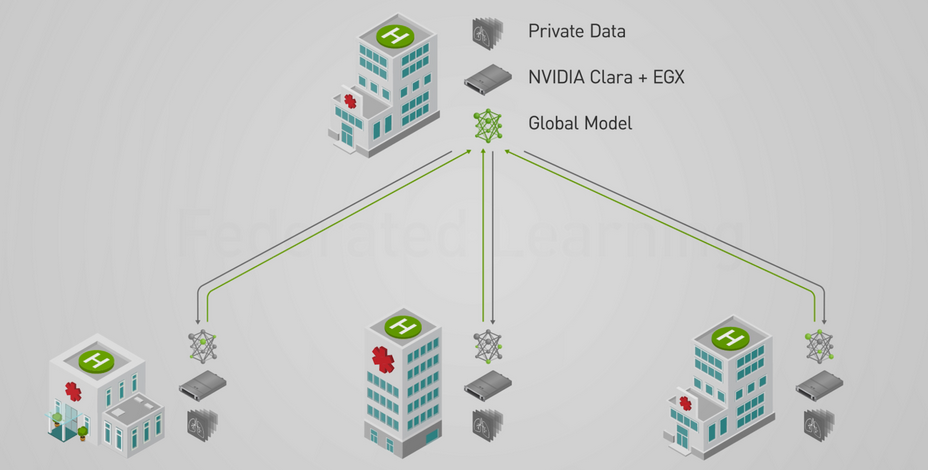
그림 7. NVIDIA EGX를 활용하여 연합 학습을 하는 Clara Train SDK
Limitations
올해 NVIDIA에서는 연합 학습에 대한 포지션 페이퍼를 내놓았다. 의료 AI 모델에 대한 대규모의 기관 내 유효성(validation) 검사에 연합 학습이 응용 가능성이 있다고 강조한다.15. 그러나 아직 연합 학습에서 해결해야 할 문제들이 많이 있다. 그 중 헬스 케어 분야에서 가장 중요한 것은 프라이버시와 보안 문제가 아닐까 싶다.
정말로 안전한가?
연합 학습에서는 원본 데이터를 공유하지는 않지만, 가중치와 같은 중간 데이터를 공유하여 글로벌 모델을 학습한다. 그러나 이러한 중간 데이터도 과연 안전하다고 볼 수 있을까? 보통은 오차를 통해 계산된 gradient를 사용하여 모델의 가중치를 업데이트하는데 최근 2019년 NIPS에서 가중치를 통해 원본 데이터를 복원하는 방법을 공개했다. 논문에서는 과연 가중치를 공유하는 전략이 각 참여자의 학습 데이터 보안에 안전한지 의문을 제기하며 Deep Leakage from Gradients(DLG) 를 소개했다.
이 방법은 아래 그림 8과 같이 다른 유저가 받은 모델을 통해 계산된 가중치(\(\nabla{W}\))에 근사한 가중치(\(\nabla{W'}\))가 생기도록 GAN 모델을 학습하여 원본 데이터를 복원하는 방법이다16. 이와 같이 가중치만으로는 훈련 데이터의 보안이 안전하다고 볼 수 없다. 그래서 대안으로 적용하는 방법이 차등 개인 정보 보호(differential privacy, DP) 이다.

그림 8. DLG 방법. 다른 참여자가 모델 학습을 통해 가중치를 얻으면 쪼꼬만 빨간 악마같은 놈이 더미값을 넣어서 얻은 가중치를 훔쳐온 가중치에 근사하도록 학습하면 다른 참여자의 원본 데이터와 근사한 데이터를 얻을 수 있다.
Defferencial Privacy 와의 연계
차등 개인 정보 보호란 개인의 정보를 유추할 수 없도록 하면서 데이터 내의 패턴을 설명하고 공개적으로 공유되는 시스템을 말한다. 이전부터 있었던 방법이지만 유명해지게 된 시점은 애플이 2016년 IOS 10에 이 시스템을 적용했다고 발표했을 때이다.
차등 개인 정보 보호에 대해 간단한 방법을 설명하자면 그림 917과 같이 \(X\)라는 데이터를 포함했을 때와 포함하지 않았을 때 두 가지 환경에서 각각의 결과 차이를 줄이는 방법이 있다. 이때 발생하는 오차인 앱실론(\(\epsilon\))이 클수록 약한 프라이버시 보호라고 하고 반대로 작을수록 강한 프라이버시 보호라고 한다.
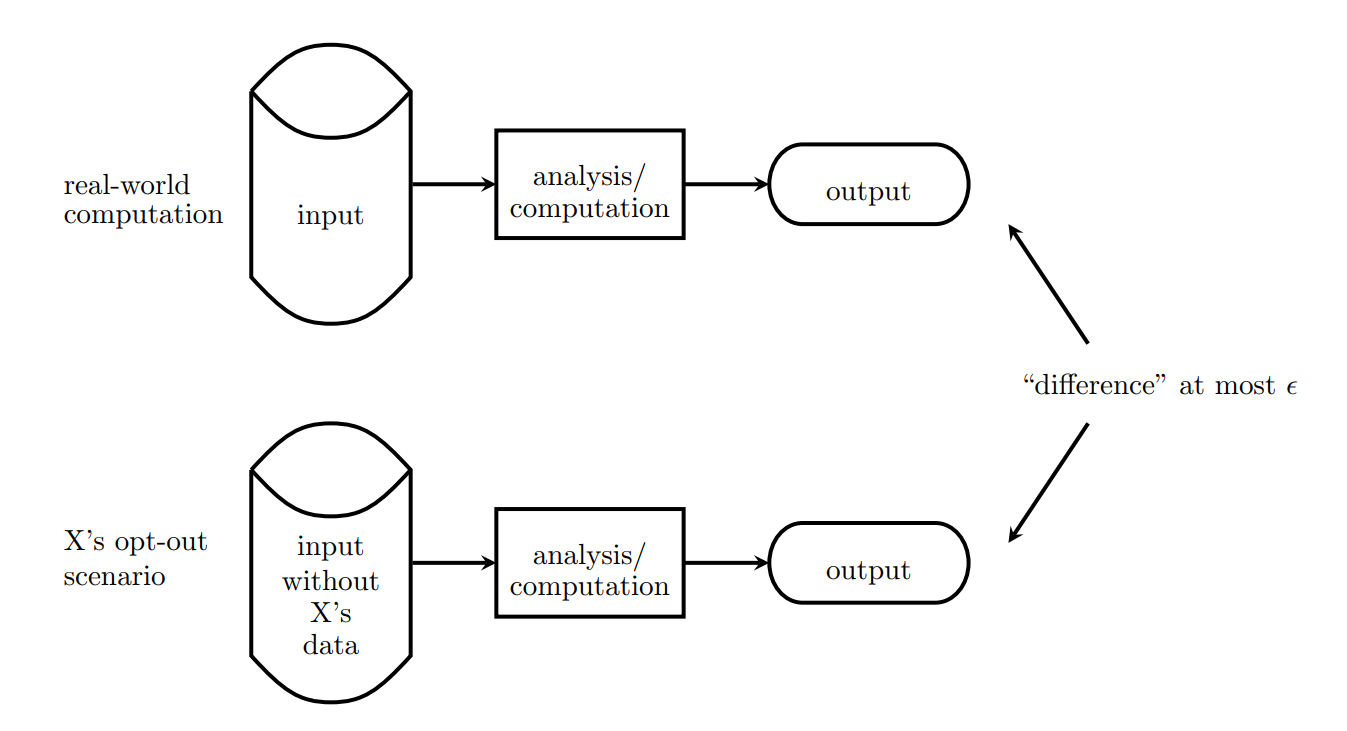
그림 9. 차등 개인 정보 보호 설명
애플의 DP overview paper를 보면 서비스마다 앱실론을 다르게 설정해서 적용하고 있다. 예를 들어 Health type 같은 경우 앱실론을 2로 정하였고 QuickType에 대해서는 앱실론을 8로 정하였다18.
EHR(Electronic Health Records) 의 경우 진단 항목이나 여러 처방에 대한 항목들이 수많은 범주를 가지고 있는 경우가 많고 이러한 데이터를 encoding 하는 경우 차원이 커지고 sparse한 성격을 갖게 되어 데이터를 활용하기 어려운 때도 있다. 이런 경우 해시 함수로 처리를 하여 -1 과 1로 이루어진 값으로 변환할 수도 있다19.
모바일 환경에서의 한계
모델이 개인 디바이스에 들어 있는 경우 학습 과정에서 발생하는 전력으로 인한 배터리 소모와 발열 문제가 있다. 그렇기에 비교적 고성능을 내기 어려운 모바일에 모델을 넣기 위해서 이전부터 모델 경량화 분야에서 많은 연구가 진행되고 있다. 가장 처음 나왔던 방법이 MobileNet 으로 기존 VGA 같은 모델보다 훨씬 더 적은 파라미터를 가지고 좋은 성능을 낼 수 있었고 이후로는 Knowledge-Distillation 과 같은 방법으로 선생과 제자와 같이 이미 좋은 성능을 내는 모델에 맞추어 크기가 작은 모델의 성능을 끌어올리는 방법이다. 넌 학생이고 난 선생이야!
Conclusion
Open Question
지금까지 간단하게 연합 학습에 대해 알아보았다. 알아보면서 여러 가지 궁금한 점들이 여전히 남아 있어서 TODO 리스트 겸 남아있는 의문점들에 대해 작성했다.
아래와 같은 질문들은 하이퍼파라미터로 휴리스틱 하게 정해야 하지 않을까 싶다. 도메인마다 기준이 있지 않을까 싶은데 각 도메인별로 어떤 기준으로 정하는지 궁금하다.
- Q. 얼마나 자주 주고받아야 하는지?
- Q. Epoch와 Batch는 어떻게 정할 것인가?
- Q. Differential Privacy를 같이 활용한다면 epsilon을 어느 정도로 정해야하는지
보안과 관련해서 궁금했던 점은 아래와 같다. 가중치를 암호화(encryption)하는 것은 가능하지만, 모델의 보안은 어떻게 지킬 것인가도 의문이다. 모델의 학습 방법이나 모델 구조 또한 보안이 필요하다고 생각된다. 다음은 특정 디바이스 또는 사용자로부터 의도적인 공격을 어떻게 탐지하고 방지할 것 인지이다. 앞서 알아봤던 결과로는 hyperparameter C로 학습할 사용자의 비율을 일부만 하거나 사용자별 가중치를 선택적으로 사용하거나 learning rate를 활용하여 학습 비중을 조절할 수 있을 것 같다. 또는 federated analytics와 같은 평가 방법을 활용하여 감지할 수 있을까 싶다.
- Q. 분산된 모델의 보안은 어떻게 유지할 것인가?
- Q. 의도적인 데이터 왜곡은 어떻게 방지할 것인가?
가중치가 노출되는 것이 문제라면 가장 근본적인 가중치를 아예 주지 않으면 되는 것이 아닐까? 라는 생각도 해볼 수 있다. 그러나 가중치 없이 학습한다는 건 아직 들어보지 못했다.
- Q. Gradient 없이 학습하는 방법이 있을까? 최적화를 하는 방법은 꼭 gradients를 기반으로 하는 것만 있는 것이 아니니 다른 방법(예를 들어 유전 알고리즘)도 충분히 고려해볼 만하다. 그러나 그만큼 성능이 좋아야 하지 않을까 싶다. 현재까지는 gradients를 어떻게 암호화할 지에 대한 연구가 중요해 보인다.
이번에는 도메인이 아니라 방법론에 대해 찾아보는 시간이었다. 오랜만에 머신러닝 관련해서 새로운 방법론을 알게 되었다는 새로움과 왜 이걸 이제 알았을까 하는 시대에 뒤처져있던 것 같은 느낌이 든다. 남들 다 하는 유행만 쫓을 때 정말 중요한 것 찾을 수 있는 눈을 갖고 싶다. 그랬으면 주식을 해서 대박이 나지 않았을까 싶다.
Reference
-
Kim, T., Heo, J., Jang, D. K., Sunwoo, L., Kim, J., Lee, K. J., … & Oh, C. W. (2019). Machine learning for detecting moyamoya disease in plain skull radiography using a convolutional neural network. EBioMedicine, 40, 636-642. ↩
-
Federated Learning: Collaborative Machine Learning without Centralized Training Data, 6 Apr 2017, Google AI Blog ↩ ↩2
-
The Mobile Economy 2020, GSMA ↩
-
McMahan, B., Moore, E., Ramage, D., Hampson, S., & y Arcas, B. A. (2017, April). Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics (pp. 1273-1282). PMLR. ↩
-
Konečný, J., McMahan, B., & Ramage, D. (2015). Federated optimization: Distributed optimization beyond the datacenter. arXiv preprint arXiv:1511.03575. ↩
-
Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. N., … & d’Oliveira, R. G. (2019). Advances and open problems in federated learning. arXiv preprint arXiv:1912.04977 ↩
-
프라이버시와 인공지능 양립 가능 솔루션 연합학습에 대하여(UNIST 이정혜), 27 May 2020, AI프렌즈 Youtube ↩ ↩2
-
Yang, Q., Liu, Y., Chen, T., & Tong, Y. (2019). Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2), 1-19. ↩
-
Federated Analytics: Collaborative Data Science without Data Collection, 27 May 2020, Google AI Blog ↩
-
Wang, K., Mathews, R., Kiddon, C., Eichner, H., Beaufays, F., & Ramage, D. (2019). Federated evaluation of on-device personalization. arXiv preprint arXiv:1910.10252. ↩
-
Ghorbani, A., & Zou, J. (2019). Data shapley: Equitable valuation of data for machine learning. arXiv preprint arXiv:1904.02868. ↩
-
Sheller, M. J., Reina, G. A., Edwards, B., Martin, J., & Bakas, S. (2018, September). Multi-institutional deep learning modeling without sharing patient data: A feasibility study on brain tumor segmentation. In International MICCAI Brainlesion Workshop (pp. 92-104). Springer, Cham. ↩
-
Federated Learning powered by NVIDIA Clara, 1 Dec 2019, NVIDIA Developer Blog ↩
-
Li, W., Milletarì, F., Xu, D., Rieke, N., Hancox, J., Zhu, W., … & Feng, A. (2019, October). Privacy-preserving federated brain tumour segmentation. In International Workshop on Machine Learning in Medical Imaging (pp. 133-141). Springer, Cham. ↩
-
Rieke, N., Hancox, J., Li, W., Milletari, F., Roth, H., Albarqouni, S., … & Ourselin, S. (2020). The future of digital health with federated learning. arXiv preprint arXiv:2003.08119. ↩
-
Zhu, L., Liu, Z., & Han, S. (2019). Deep leakage from gradients. In Advances in Neural Information Processing Systems (pp. 14774-14784). ↩
-
Understanding Differential Privacy, 1 Jul 2019, An Nguyen ↩
-
Differential Privacy Overview, Apple ↩
-
Lee, J., Sun, J., Wang, F., Wang, S., Jun, C. H., & Jiang, X. (2018). Privacy-preserving patient similarity learning in a federated environment: development and analysis. JMIR medical informatics, 6(2), e20. ↩
Leave a comment